0.8.0 Release Notes
Zig is a general-purpose programming language and toolchain for maintaining robust, optimal, and reusable software.
Backed by the Zig Software Foundation, the project is financially sustainable and offers billable hours for core team members:
Please consider donating to the ZSF to help us pay even more contributors!
This release features 7 months of work and changes from 144 different contributors, spread among 2711 commits.
Table of Contents §
- Table of Contents
- Support Table
- Documentation
- Language Changes
- Bootstrap Compiler
- Self-Hosted Compiler
- CPU Feature Detection
- Command-Line Interface
- Reworked Memory Layout
- Whole-File AST Lowering
- LTO
- Static PIE
- Native libc Integration
- Reuse Runtime Libraries in More Cases
- x86-64 Backend
- AArch64 Backend
- ARM Backend
- LLVM Backend
- WebAssembly Backend
- RISC-V 64 Backend
- C Backend
- SPIR-V Backend
- SPU Mark II Backend
- Miscellaneous stage2 Improvements
- Self-Hosted Linker
- C Translation
- Standard Library
- Zig Build System
- Toolchain
- Bug Fixes
- News
- Roadmap
- Thank You LavaTech
- Thank You Sponsors!
Support Table §
Tier System §
A green check mark (✅) indicates the target meets all the requirements for the support tier. The other icons indicate what is preventing the target from reaching the support tier. In other words, the icons are to-do items. If you find any wrong data here please submit a pull request!
Tier 1 Support §
- Not only can Zig generate machine code for these targets, but the standard library cross-platform abstractions have implementations for these targets.
- 🧪 The CI server automatically tests these targets on every commit to master branch.
- 📦 The CI server automatically produces pre-built binaries for these targets, on every commit to master, and updates the download page with links.
- These targets have debug info capabilities and therefore produce stack traces on failed assertions.
- libc is available for this target even when cross compiling.
- 🐛 All the behavior tests and applicable standard library tests pass for this target. All language features are known to work correctly. Experimental features do not count towards disqualifying an operating system or architecture from Tier 1.
zig cc,zig c++and related toolchain commands support this target.- 💀 If the Operating System is proprietary then the target is not marked deprecated by the vendor, such as macos/x86.
| freestanding | Linux 3.16+ | macOS 10.13+ | Windows 8.1+ | WASI | |
|---|---|---|---|---|---|
| x86_64 | ✅ | ✅ | ✅ | ✅ | N/A |
| x86 | ✅ | #1929 🐛📦 | 💀 | #537 🐛📦 | N/A |
| aarch64 | ✅ | #2443 🐛 | ✅ | 🐛📦🧪 | N/A |
| arm | ✅ | #3174 🐛📦 | 💀 | 🐛📦🧪 | N/A |
| mips | ✅ | #3345 🐛📦🧪 | N/A | N/A | N/A |
| riscv64 | ✅ | #4456 🐛📦 | N/A | N/A | N/A |
| sparcv9 | ✅ | #4931 🐛📦🧪 | N/A | N/A | N/A |
| wasm32 | ✅ | N/A | N/A | N/A | ✅ |
Tier 2 Support §
- 📖 The standard library supports this target, but it's possible that some APIs will give an "Unsupported OS" compile error. One can link with libc or other libraries to fill in the gaps in the standard library.
- 🔍 These targets are known to work, but may not be automatically tested, so there are occasional regressions.
- Some tests may be disabled for these targets as we work toward Tier 1 Support.
| free standing | Linux 3.16+ | macOS 10.13+ | Windows 8.1+ | FreeBSD 12.0+ | NetBSD 8.0+ | DragonFlyBSD 5.8+ | UEFI | |
|---|---|---|---|---|---|---|---|---|
| x86_64 | Tier 1 | Tier 1 | Tier 1 | Tier 1 | ✅ | ✅ | ✅ | ✅ |
| x86 | Tier 1 | ✅ | 💀 | ✅ | 🔍 | 🔍 | N/A | ✅ |
| aarch64 | Tier 1 | ✅ | Tier 1 | 🔍 | 🔍 | 🔍 | N/A | 🔍 |
| arm | Tier 1 | ✅ | 💀 | 🔍 | 🔍 | 🔍 | N/A | 🔍 |
| mips64 | ✅ | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | N/A |
| mips | Tier 1 | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | N/A |
| powerpc64 | ✅ | 📖 | 💀 | N/A | 🔍 | 🔍 | N/A | N/A |
| powerpc | ✅ | ✅ | 💀 | N/A | 🔍 | 🔍 | N/A | N/A |
| riscv64 | Tier 1 | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | 🔍 |
| sparcv9 | Tier 1 | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | N/A |
Tier 3 Support §
- The standard library has little to no knowledge of the existence of this target.
- If this target is provided by LLVM, LLVM has the target enabled by default.
- These targets are not frequently tested; one will likely need to contribute to Zig in order to build for these targets.
- The Zig compiler might need to be updated with a few things such as
- what sizes are the C integer types
- C ABI calling convention for this target
- start code and default panic handler
zig targetsis guaranteed to include this target.
| freestanding | Linux 3.16+ | Windows 8.1+ | FreeBSD 12.0+ | NetBSD 8.0+ | UEFI | |
|---|---|---|---|---|---|---|
| x86_64 | Tier 1 | Tier 1 | Tier 1 | Tier 2 | Tier 2 | Tier 2 |
| x86 | Tier 1 | Tier 2 | Tier 2 | ✅ | ✅ | Tier 2 |
| aarch64 | Tier 1 | Tier 2 | ✅ | ✅ | ✅ | ✅ |
| arm | Tier 1 | Tier 2 | ✅ | ✅ | ✅ | ✅ |
| mips64 | Tier 2 | Tier 2 | N/A | ✅ | ✅ | N/A |
| mips | Tier 1 | Tier 2 | N/A | ✅ | ✅ | N/A |
| riscv64 | Tier 1 | Tier 2 | N/A | ✅ | ✅ | ✅ |
| powerpc32 | Tier 2 | Tier 2 | N/A | ✅ | ✅ | N/A |
| powerpc64 | Tier 2 | ✅ | N/A | ✅ | ✅ | N/A |
| bpf | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| hexagon | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| amdgcn | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| sparc | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| s390x | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| lanai | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| csky | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| freestanding | emscripten | |
|---|---|---|
| wasm32 | Tier 1 | ✅ |
Tier 4 Support §
- Support for these targets is entirely experimental.
- If this target is provided by LLVM, LLVM may have the target as an
experimental target, which means that you need to use Zig-provided binaries
for the target to be available, or build LLVM from source with special configure flags.
zig targetswill display the target if it is available. - This target may be considered deprecated by an official party, such as macosx/i386 in which case this target will remain forever stuck in Tier 4.
- This target may only support
-femit-asmand cannot emit object files (-fno-emit-binenabled by default and cannot be overridden).
Tier 4 targets:
- avr
- riscv32
- xcore
- nvptx
- msp430
- r600
- arc
- tce
- le
- amdil
- hsail
- spir
- kalimba
- shave
- renderscript
- 32-bit x86 macOS, 32-bit ARM macOS, powerpc32 and powerpc64 macOS, because Apple has officially dropped support for them.
Windows Support §
Improvements to the Standard Library:
- Avoid redundantly providing Windows TLS startup symbols when linking libc because they are already provided by libcrt.
- Add
timevalextern struct. - Made sure to handle PATH_NOT_FOUND when deleting files (#7879).
- Made windows.ReadFile allow short reads (#7121).
- Implement chdir and chdirZ for Windows.
- Fixed WindowsDynLib.openW trying to strip the \??\ prefix when it does not exist.
- Only check for evented mode in windows.OpenFile when in async mode.
- Introduced os.windows.QueryObjectName
- os.windows.GetFinalPathNameByHandle: add test
- Define nfds_t for windows.
- os.windows.user32.messageBoxW.
- os/windows/ws2_32: add missing FIONBIO constant.
- Fixed and add os.windows.user32 WM constants.
- Implemented nt path conversion for windows. Fixes
.and..not working instd.fspaths. - Switched to using unicode when parsing the command line on windows (#7241).
No MSVC Dependency by Default §
Since Zig ships with MinGW-w64, Zig can be used to compile C and C++ code on Windows without having MSVC installed. However, before this release, it was not obvious how to take advantage of this feature, since the default behavior was to integrate with MSVC.
In this release, the default behavior is to ignore MSVC and do everything based only on the Zig installation. This makes using Zig to compile C and C++ code on Windows an "it just works" experience.
MSVC integration can be achieved by using -target native-native-msvc.
Note that mingw-w64 is ABI-compatible with MSVC, so any build artifacts produced by one
are consumable by the other. However the respective C header files are not always
API-compatible, which is why there is still a use case for overriding the default.
Tracking issue: #6565
macOS Support §
With the advent of the Self-Hosted Linker, Zig is now able to generate well-formed and codesigned binaries on arm64 macOS (aka the Apple Silicon). It is also able to cross-compile C, C++, and Zig code to an arm64 and x86_64 macOS. Additionally, arm64 nightly binaries of Zig are automatically generated by our Continuous Integration service, meaning both arm64 and x86_64 macOS are now Tier 1 targets.
To facilitate incremental linking, the self-hosted compiler is now by default generating
dSYM bundles which store DWARF debug information and debug symbols on macOS.
This puts Zig on path of becoming a true replacement for the Xcode development environment.
Finally, as a side experiment, Jakub added in Zig Build System integration
with Darling (#8760), a translation layer of macOS
syscalls to Linux, with the intention of being able to cross test MachO binaries
and macOS specific tests directly on Linux simply by passing in an additional flag
-Denable-darling to zig build test.
In 0.8.0, Zig provides libc header files for macOS, for both
x86_64-macos and aarch64-macos, using the experimental
fetch-them-macos-headers
project. There is a myth that Apple's C header files have an encumbered license, but that is not
the case. They are licensed under the
Apple Public Source License
which is in fact quite permissive.
Zig 0.8.0 relies on these headers even when compiling natively, as long as there are no system dependencies. This makes Zig able to compile C and C++ code on macOS without XCode installed (#6773).
Additionally, OS version detection for macOS has been re-implemented.
WebAssembly Support §
The Self-Hosted Compiler gained a work-in-progress WebAssembly Backend, which provides the ability for Zig to compile to wasm without LLVM.
Zig now ships with WASI libc and supports cross-compiling C code to WASI. This also makes Zig a tempting alternative to downloading and building WASI libc and/or WASI SDK manually (#8837).
Additionally:
- Zig now uses the standard
.oextension for wasm objects rather than.o.wasm. - Just like every other target,
zig build-libnow builds a static archive for wasm, unless-dynamicis specified.
Haiku Support §
Al Hoang contributed some initial work to get Zig to run under Haiku. Some things that are now working:
- zig cc of a barebones C program appears to compile.
zig build-execan generate an executable binary.zig runon a zig file works.- Some basic Standard Library abstractions are implemented for Haiku.
Getting stack traces to work is still in-progress.
csky Support §
LLVM 12 brings in csky support. glibc already supported csky, but Zig did not ship glibc header files for it since LLVM did not have a backend for it. Zig 0.8.0 additionally ships glibc header files for csky.
csky is now a Tier 3 target.
thumb2 Support §
LemonBoy contributed the initial bringup for Linux/Thumb2 (#8683).
Improved support for building musl and glibc in thumb mode.
Pass -mthumb when compiling C/C++ code. The Clang driver requires this flag and ignores the target triple.
bpf Support §
Matthew Knight added the c_longdouble mapping for bpf (#7504).
msp430 Support §
Nathan Michaels added the c_longdouble mapping for msp430 (#7333).
sparc64 Support §
sparcv9 gets promoted to Tier 2 in this release due to various improvements:
- Fixed
fork()on Linux/sparc64 and add long double mapping (#7237). - stage1: set gen_frame_size alignment to work around requirement mismatch.
- Added compiler-rt stub for SPARC CPUs.
- stage1: SPARCv9 f128 enablement (#7716).
- Handle various stack frame related quirks (#7946).
- Fixed backtraces on sparcv9.
- std: Fix stack overflow in SPARC clone() impl
- std: Import correct errno defs for SPARC
- std: Add signal numbers for SPARC
- std: Fix pwrite/pread syscalls on SPARC targets
- Define ENOTSUP for SPARC.
- Fix linux dirent64 buffer align directive.
Contributors: Koakuma, LemonBoy
PowerPC Support §
32-bit PowerPC gets promoted to Tier 2 in this release due to various improvements:
- PPC: Correct the generic feature set
- PPC64: Use newfstatat on PPC64.
- PPC64: Use correct clone() stub.
- target: map zig ppc32 → llvm ppc (#7947).
- compiler-rt: Don't re-define PPC builtins in test mode
Zig now has CI test coverage for powerpc-linux-none and
powerpc-linux-musl. The issue blocking glibc support
is #4927.
Contributors: LemonBoy, lithdew, Michael Dusan, Benjamin Feng
32-bit x86 Support §
LemonBoy made progress working around #4926, preventing Zig from being able
to build glibc on i386-linux-gnu.
He got it working, and the tests passing, but it revealed a
flaw (#8930) in the Standard Library having to do with allocation alignments
on all 32-bit targets. This issue is not solved in 0.8.0 but is planned to be
addressed in the 0.8.1 bug fix release. After that, we expect to have test
coverage for i386-linux-gnu.
MIPS Support §
During the 0.8.0 release cycle, Zig's MIPS support was greatly improved, gaining full test coverage for little-endian mips, including building musl and glibc.
However, all MIPS targets regressed with the release of LLVM 12, despite having an open release blocker bug filed. Not only this, but the fix has been in LLVM main branch for a whole month, as of the time of this writing, and yet the fix did not make it into 12.0.1-rc1, again despite the bug being marked as a 12.0.1 release blocker.
As soon as LLVM releases a bug fix version which includes the fix, Zig can re-enable MIPS test coverage.
Documentation §
- std docs: enhance search browser history UX
- The language reference is updated to reflect the changes to the language and standard library in this release cycle.
- Fixed
@reducedocumentation. - Fixed operator precedence in the language reference.
- Improved documentation for string slices (#7454).
- Clarify confusing wording regarding
%and/ - Clarify that
@fieldcan work on declarations. - Avoid concept of a "Unicode character" in documentation and error messages (#8059).
- Update docs and grammar to allow CRLF line endings (#8063).
- langref: Use "single-item pointer" and "many-item pointer" (#8217).
- docgen: use
std.ProgressAPI so that we see a terminal progress bar when waiting for the docs to build. - docs: document the nosuspend keyword (#7972).
- Fix langref.html anchor navigation
- Add doc in `Anonymous Struct Literal` section for special @"0" syntax (#8630).
- Improve documentation for ArrayList, ArrayListUnmanaged, etc. (#7624)
Contributors: Andrew Kelley, Carlos Zúñiga, Dave Gauer, Devin Bayer, Eleanor Bartle, Frank Denis, Jakub Konka, Jay Petacat, Jonas Carpay, Josh Holland, Josh Wolfe, LemonBoy, Martin Wickham, Mathieu Guay-Paquet, Matthew Borkowski, Ryan Liptak, Tadeo Kondrak, Veikka Tuominen, data-man, Jacob G-W, xackus
Language Changes §
Compared to other releases, the Zig language saw fewer changes this cycle, providing a relatively stable target for the Self-Hosted Compiler implementation. Still, there were a few additions and breaking changes.
No More Extern or Packed Enums §
const A = extern enum { foo, bar };
const B = packed enum { foo, bar };test.zig:1:11: error: enums do not support 'packed' or 'extern'; instead provide an explicit integer tag type
const A = extern enum { foo, bar };
^
test.zig:2:11: error: enums do not support 'packed' or 'extern'; instead provide an explicit integer tag type
const B = packed enum { foo, bar };
^This error is caught by the Self-Hosted Compiler (due to Whole-File AST Lowering) but not yet caught by the Bootstrap Compiler. Related proposal: #8970
Require Block After Suspend §
test.zig
test "example" {
suspend;
}$ zig test test.zig
./docgen_tmp/test.zig:2:12: error: invalid token: ';'
suspend;
^
zig fmt automatically fixes it, transforming it into:
test "example" {
suspend {}
}Tracking issue: #8603
@extern §
New builtin:
@extern(T: type, comptime options: std.builtin.ExternOptions) *TCreates a reference to an external symbol in the output object file.
Nameless Tests §
Nameless tests are exempt from --test-filter parameters, making it
possible to use --test-filter while still pointing zig test
at the root source file.
a.zig
test {
_ = @import("b.zig");
}b.zig
const std = @import("std");
test "pass" {
try std.testing.expect(true);
}
test "fail" {
try std.testing.expect(false);
}$ ./zig test a.zig
b.test "fail"... FAIL (TestUnexpectedResult)
/home/andy/Downloads/zig/lib/std/testing.zig:310:14: 0x24d54b in std.testing.expect (test)
if (!ok) return error.TestUnexpectedResult;
^
/home/andy/Downloads/zig/build/b.zig:7:5: 0x2068b1 in b.test "fail" (test)
try std.testing.expect(false);
^
2 passed; 0 skipped; 1 failed.
error: the following test command failed with exit code 1:
zig-cache/o/577deb476721d8dde8bc782f2c61ed2f/test /home/andy/Downloads/zig/build/zig
$ ./zig test a.zig --test-filter pass
All 2 tests passed.@TagType Removed §
Old code:
test.zig
const std = @import("std");
const Enum = enum { one, two, three };
test "old code" {
const T = @TagType(Enum);
try std.testing.expectEqual(u2, T);
}$ zig test test.zig
./docgen_tmp/test.zig:5:15: error: invalid builtin function: 'TagType'
const T = @TagType(Enum);
^
New code:
test.zig
const std = @import("std");
const Enum = enum { one, two, three };
const TagType = std.meta.TagType;
test "new code" {
const T = TagType(Enum);
try std.testing.expectEqual(u2, T);
}$ zig test test.zig
Test [1/1] test "new code"...
All 1 tests passed.
Contributors: Tadeo Kondrak
nosuspend §
nosuspend blocks now allow resume
inside their scope, because resuming a suspended async function call is actually a
synchronous operation.
nosuspend blocks now allow async
function calls inside their scope, because starting an async function call is actually
a synchronous operation, since the caller is not awaiting on the callee for a return value.
Add SysV Calling Convention §
std.builtin.CallingConvention now looks like this:
pub const CallingConvention = enum {
Unspecified,
C,
Naked,
Async,
Inline,
Interrupt,
Signal,
Stdcall,
Fastcall,
Vectorcall,
Thiscall,
APCS,
AAPCS,
AAPCSVFP,
SysV,
};Wrapping Negation on Unsigned Ints at comptime §
test.zig
const std = @import("std");
const expect = std.testing.expect;
const maxInt = std.math.maxInt;
test "unsigned negation wrapping" {
try testUnsignedNegationWrappingEval(1);
comptime try testUnsignedNegationWrappingEval(1);
}
fn testUnsignedNegationWrappingEval(x: u16) !void {
try expect(x == 1);
const neg = -%x;
try expect(neg == maxInt(u16));
}$ zig test test.zig
Test [1/1] test "unsigned negation wrapping"...
All 1 tests passed.
Contributor: LemonBoy
@import("builtin") no longer re-exports std.builtin §
Old code:
test.zig
const std = @import("std");
const builtin = @import("builtin"); // <--- look here
test "old code" {
const StackTrace = builtin.StackTrace;
}$ zig test test.zig
./docgen_tmp/test.zig:5:31: error: container 'builtin' has no member called 'StackTrace'
const StackTrace = builtin.StackTrace;
^
New code:
test.zig
const std = @import("std");
const builtin = std.builtin; // <--- look here
test "new code" {
const StackTrace = builtin.StackTrace;
}$ zig test test.zig
Test [1/1] test "new code"...
All 1 tests passed.
Additionally, the following is deprecated:
const std = @import("std");
const builtin = std.builtin; // <--- look here
test "deprecated code" {
const native_arch = builtin.cpu.arch; // deprecated!
}Instead, do this:
test.zig
const std = @import("std");
const builtin = @import("builtin"); // <--- look here
test "new code" {
const native_arch = builtin.cpu.arch; // OK
}$ zig test test.zig
Test [1/1] test "new code"...
All 1 tests passed.
Bootstrap Compiler §
In the previous release, as well as this release, the main Zig compiler everybody uses is the bootstrap compiler, written in C++, also known as "stage1". Despite the main focus of this release cycle being the Self-Hosted Compiler, there were some improvements to stage1 as well.
- Fix not supporting comments in between multiline string literal lines
- Fix type mapping for c_longdouble
- Print correct error message for vector @intCast
- Fix comparison of unions containing zero-sized types (#7047)
- Avoid resolving type entry in [0]T (fixed #7058)
- Fix crash in comptime struct generation (#7027)
- Disambiguate Wasm imports with same name (#7088)
- Fix generation of pass-by-value args in async fns (#7104)
- Fix asyncCall with non-abi-aligned arguments
- Add architecture-specific clobbers to asm(). We're basically following Clang's lead, add the necessary clobbers to minimize the risk of generating wrong code.
- Allow Zig to be built with clang 11 and -Werror
- Reject undefined values when taking union ptr. (#7019)
- Improve error for missing a number type on a runtime var.
- Fix undefined assignment for bitfields. Prevents silent memory corruption. (#7055)
- Emit a compile error instead of falling back to C for unsupported calling convention. (#6829)
- Check calling convention correctly for subsystem detection.
- Resolve usingnamespace decls when calling
@typeInfo(#7176). - Fix ICE when generating struct fields with padding. (#5398)
- Force union member types to be resolved.
- Fix crash in *[N]T to []T conversion with zst (#6951).
- Add compile error for slice.len incremented beyond bounds (#7810).
- Fix
f128codegen on Big Endian hosts. - Resolve alignment earlier in
@alignCast(#7744). - Use correct format specifier for size_t parameters.
- Fix ssize_t definition.
- Remove stray brace in rarely-tested code path (#7614).
- Allow variable capture for multi-prong switch arms, handling the multi-prong case as we do with range cases (#7188).
- Let LLVM legalize the overflowing ops on vectors, because it is smart enough to produce tight overflow checking sequences.
- Prevent crash with some lazy pointer types (#7568).
- Validate pointer attributes when coercing anon literals.
- Implement type coercion of pointer to anon list to array/struct/union/slice.
- Implement type coercion of anon list to array.
- Create a new declaration scope for union enum types (#7532).
- Add peer type resolution with unsigned ints and larger signed ints.
- Fix bug in generic function monomorphization.
- Apply LLVM ssp attributes globally instead of per-function. Otherwise LLVM asserts with: "stack protected callee but caller requested no stack protector"
- Fix crashes (#7426, #7451, #7431).
- Validate the specified cc for lazy fn types (#7337).
- Fix initialization of single-element union tag.
- Fix constant folding of single-element enums.
- Add compile error for pointer arithmetic on ptr-to-array (#2018).
- Fix floating point parsing on BE systems (#7256).
- Fix typeInfo generation for arrays w/o sentinel (#7251).
- Add missing bitcast when rendering var ptr (#7250).
- Small improvement in C ABI support for return types.
- A few small memory usage optimizations.
- Put async frames in the correct LLVM address space.
- Fix for atomicrmw xchg on fp types (#4457).
- Rework tokenizer to match Self-Hosted Compiler. Mainly, this makes the stage1 and stage2 logic match each other, making it easier to maintain both at the same time. It is also a negligible memory usage improvement.
- Store target info in the LLVM module for every function. This is needed to let LLVM (or, better, libLTO) produce code using the target options specified by the user (#8803).
- Widen non byte-sized atomic loads/stores (#7976).
- Improve message for missing fn return type.
- Fix LLVM error in inline asm invocation (#3606).
- Improve how the async frame alignment is computed.
- More precise serialization of f16 values.
- Fix negation for zero floating point values.
- Resolve builtin types and values via
std.builtinrather than via@import("builtin"). This helps avoid the need forusingnamespaceused inbuiltin.zigor instd.builtin.
The good news here is that nearly all these fixes come with additional behavior tests, which we can use to verify the Self-Hosted Compiler does not regress.
One especially noteworthy change here is LemonBoy's fix to ask LLVM to produce compact code in -OReleaseSmall mode. Previously, using -OReleaseSmall sometimes resulted in larger output binaries than -OReleaseFast! (#7048, #7077)
Big, big thanks to LemonBoy for solving so many stage1 bugs during this release cycle. This is high effort, low-appreciation, huge-impact work that he has been doing. But in reality he has been single-handedly keeping us afloat while we work towards finishing the Self-Hosted Compiler.
Contributors: LemonBoy, Andrew Kelley, Koakuma, Veikka Tuominen, Tadeo Kondrak, Michael Dusan, Jakub Konka, frmdstryr, Mathieu Guay-Paquet, Sreehari S, Al Hoang, Alexandros Naskos, Isaac Freund, Jay Petacat, Josh Wolfe, Lee Cannon, Matthew Knight, Nathan Michaels, Sizhe Zhao, Timon Kruiper, Woze Parrot, Jacob G-W, lars, pfg, xackus
LLVM 12 §
This release of Zig upgrades to LLVM 12.
This was a rough release cycle for downstream users of LLVM. During testing of the release candidates, we found and reported 7 regressions from LLVM 11. However, despite having reproducible regressions reported as release blockers, the LLVM project tagged release 12.0.0. Not only were there open regressions at this time, but the 12.0.0 tag did not even tag the tip of the release/12.x branch - so there were fixes already committed into the release branch that did not make it into the tag.
At the time of this writing, there are 31 open release blockers for 12.0.1, and yet LLVM has already tagged 12.0.1-rc1. As Michał Górny puts it:
I've started testing, hit two bugs I've already reported for 12.0.0 RCs and figured out I'm wasting my time. It seems that LLVM reached the point where releases are pushed through just for the sake of releases and QA doesn't exist.
I hope the LLVM project can step up and take releases and regressions more seriously.
Either way, it is starting to become clear that transitioning LLVM to an optional dependency, and thereby providing an alternative to the LLVM monoculture, is becoming more and more of an attractive feature for the Zig project to offer. In this release you can see that we have broken ground on this front: x86-64 Backend, AArch64 Backend, ARM Backend, WebAssembly Backend, RISC-V 64 Backend, C Backend, SPIR-V Backend
Self-Hosted Compiler §
The main focus of this release cycle was the self-hosted compiler (also known as "stage2").
Despite the fact that .zig source code by default is still compiled in this release using the Bootstrap Compiler, the main driver code is already self-hosted, as well as many features, such as zig cc, C Translation, and CPU Feature Detection. Improvements made to "stage2" in these areas do in fact affect the main Zig user experience.
CPU Feature Detection §
LemonBoy added a framework for host CPU detection on Linux based on
parsing /proc/cpuinfo, and implemented the model
detection for 64-bit SPARC targets as proof of concept.
He also added CPU feature detection for macOS, PowerPC, and ARM/AArch64.
The CPU detection code is nearly at feature parity with LLVM. We do support detecting the native CPU on Sparc systems and macOS, our ARM/AArch64 model list is quite comprehensive, and so is our PPC one. The only missing pieces are:
- ARM32 detection on Darwin hosts (it is doubtful anybody is planning on running the compiler on a old-ass iPhone)
- s390x detection on Linux hosts. This can be easily added at a later stage.
As a result of all this work, we dropped LLVM's host CPU detection method as a fallback. This is one less dependency that Zig has on LLVM, bringing us one step closer to making LLVM an optional extension rather than a required dependency.
Update CPU Features Tool §
Zig's target CPU feature awareness is a superset of LLVM's, which means that for every target CPU feature Zig is aware of, it must know whether and how to map that to LLVM's target CPU feature.
For this purpose Andrew created the update_cpu_features.zig tool. This tool generates .zig code that contains enums and data declarations for all the various CPUs that Zig is aware of.
This tool is run in response to the following two events:
- When a new LLVM version is released.
- When the Zig project modifies, creates, or deletes target CPU features independently of LLVM.
Before this release, updating target CPU features in response to LLVM updates was a manual process, in which it was too easy to introduce bugs.
Now, the tool completely automates the process, and there are no longer any manual steps involved when LLVM updates, other than re-running the tool.
Additionally, Andrew improved it to parallelize work for each target, making it run much faster, despite wading through many megabytes of llvm-tblgen JSON dumps.
Command-Line Interface §
- Fixed
zig init-libnot accepting-hflag (#6798). - Infer
--namebased on first C source file or object. - Fixed incorrect error message with
-cflags. - Added
runandupdate-and-runcommand to the--watchREPL. - In the
--watchREPL, empty command re-runs previous command. This can be especially useful combined with the newupdate-and-runcommand.
Reworked Memory Layout §
Andrew writes:
I have been reading Richard Fabian's book, Data-Oriented Design, and finally things started to "click" for me. I've had these ideas swirling around in my head for years, but only recently do I feel like I have an intuitive grasp on how modern CPUs work, especially with regards to L1 cache, and the relative latencies of uncached memory loads vs computations.
Compilation speed is a top priority for the design of both the Zig self-hosted compiler as well as the language itself. I have been careful to design the language in a way as to unlock the potential of an ambitiously fast compiler.
In this release cycle, I took the time to rework the memory layout of 3 out of 4 phases of the compiler pipeline:
tokenize ➡️ parse ➡️ ast lowering ➡️ semantic analysis ➡️ machine code gen
Each arrow in this diagram represents a phase in the compiler pipeline inputting data in one form, and outputting data in a different form, for the next phase.
- tokenize - inputs .zig source code, outputs token list
- parse - inputs token list, outputs AST (Abstract Syntax Tree)
- ast lowering - inputs AST, outputs ZIR (Zig Intermediate Representation)
- semantic analysis - inputs ZIR, outputs AIR (Analyzed Intermediate Representation)
- machine code gen - inputs AIR, outputs machine code
I decided to try to reduce the number of heap-allocated bytes of the token list as well as the AST, as a pilot test for doing a similar strategy for ZIR and AIR later. I had a few key insights here:
- Underlying premise: using less memory will make things faster, because of fewer allocations and better cache utilization. Also using less memory is valuable in and of itself.
- Using a Struct-Of-Arrays for tokens and AST nodes, saves the bytes of padding between the enum tag (which kind of token is it; which kind of AST node is it) and the next fields in the struct. It also improves cache coherence, since one can peek ahead in the tokens array without having to load the source locations of tokens.
- Token memory can be conserved by only having the tag (1 byte) and byte offset (4 bytes) for a total of 5 bytes per token. It is not necessary to store the token ending byte offset because one can always re-tokenize later, but also most tokens the length can be trivially determined from the tag alone, and for ones where it doesn't, string literals for example, one must parse the string literal again later anyway in astgen, making it free to re-tokenize.
- AST nodes do not actually need to store more than 1 token index because one can poke left and right in the tokens array very cheaply.
So far we are left with one big problem though: how can we put AST nodes into an array, since different AST nodes are different sizes?
This is where my key observation comes in: one can have a hash table for the extra data for the less common AST nodes! But it gets even better than that:
I defined this data that is always present for every AST Node:
- tag (1 byte)
- which AST node is it
- main_token (4 bytes, index into tokens array)
- the tag determines which token this points to
struct{lhs: u32, rhs: u32}- enough to store 2 indexes to other AST nodes, the tag determines how to interpret this data
You can see how a binary operation, such as a * b would fit into this
structure perfectly. A unary operation, such as *a would also fit,
and leave rhs unused. So this is a total of 13 bytes per AST node.
And again, we don't have to pay for the padding to round up to 16 because
we store in struct-of-arrays format.
I made a further observation: the only kind of data AST nodes need to store other than the main_token is indexes to sub-expressions. That's it. The only purpose of an AST is to bring a tree structure to a list of tokens. This observation means all the data that nodes store are only sets of u32 indexes to other nodes. The other tokens can be found later by the compiler, by poking around in the tokens array, which again is super fast because it is struct-of-arrays, so you often only need to look at the token tags array, which is an array of bytes, very cache friendly.
So for nearly every kind of AST node, you can store it in 13 bytes. For the rarer AST nodes that have 3 or more indexes to other nodes to store, either the lhs or the rhs will be repurposed to be an index into an extra_data array which contains the extra AST node indexes. In other words, no hash table needed, it's just 1 big ArrayList with the extra data for AST Nodes.
Final observation, no need to have a canonical tag for a given AST. For example:
The expression foo(bar) is a function call. Function calls can have any
number of parameters. However in this example, we can encode the function
call into the AST with a tag called FunctionCallOnlyOneParam, and use lhs
for the function expr and rhs for the only parameter expr. Meanwhile if the
code was foo(bar, baz) then the AST node would have to be FunctionCall
with lhs still being the function expr, but rhs being the index into
extra_data. Then because the tag is FunctionCall it means
extra_data[rhs] is the "start" and extra_data[rhs+1] is the "end".
Now the range extra_data[start..end] describes the list of parameters
to the function.
Point being, you only have to pay for the extra bytes if the AST actually requires it. The limit to the number of different AST tag encodings is 256, in order to keep the tag only 1 byte each.
Reworking the memory layout of two of the core pipeline phases is no joke. After 176 commits, 42 files changed, +20,800/-16,573 lines, and help from quite a few contributors, we had all tests passing again in the branch (#7920). I observed the following performance improvements of the parser:
- ✅ 15% fewer cache-misses
- ✅ 28% fewer total instructions executed
- ✅ 26% fewer total CPU cycles
- ✅ 22% faster wall clock time
Based on this success, I followed up, applying the same principles and strategies to ZIR.
I'll spare you the details this time, but after 100 commits, 33 files changed, +14,719/-11,495 lines, and again some very much appreciated help from various contributors, the branch was merge-ready (#8266).
For these changes, it was not possible to come up with a realistic workload for a benchmark, since self-hosted semantic analysis was not far enough along, but I was able to do this funny one:
print1mil.zig
pub export fn _start() noreturn {
print(); // repeated 1,000,000 times
exit();
}
fn print() void {
asm volatile ("syscall"
:
: [number] "{rax}" (1),
[arg1] "{rdi}" (1),
[arg2] "{rsi}" (@ptrToInt("Hello, world!\n")),
[arg3] "{rdx}" (14)
: "rcx", "r11", "memory"
);
return;
}
fn exit() noreturn {
asm volatile ("syscall"
:
: [number] "{rax}" (231),
[arg1] "{rdi}" (0)
: "rcx", "r11", "memory"
);
unreachable;
}Results:
- ✅ Wall Clock Time: 0.93 seconds ➡️ 0.57 seconds (39% reduction)
- this is 1.8 million lines per second on my laptop 😀
- ✅ Peak Memory Usage: 645 MiB ➡️ 386 MiB (40% reduction)
- ✅ Cache Misses (53% reduction)
- ✅ Instructions (23% reduction)
- ✅ CPU Cycles (41% reduction)
Even with a contrived example like this, it is clear that designing the core phases of the compiler pipeline to use compact encodings has an obvious and worthwhile benefit in terms of memory usage and speed.
In this release we did not yet apply these principles and strategies to AIR, the last remaining intermediate representation of the compiler pipeline. When we do, it will affect the bottleneck of the compiler - semantic analysis and machine code generation - and so I expect to see similar performance gains upon finishing that work.
Whole-File AST Lowering §
This was a language modification as well as an implementation strategy. It solves #335 and goes a long way towards making the problematic proposal #3028 unneeded. The implementation simplified the compiler and yet opened up straightforward opportunities for parallelism and caching.
In stage2 we have a concept of "AstGen" which stands for Abstract Syntax Tree Generation. This is the part where we input an AST and output Zig Intermediate Representation code.
Before, this was done lazily as-needed per function. This required code to orchestrate per-function ZIR code and independently manage memory lifetimes. It also meant each function used independent arrays of ZIR tags, instruction lists, string tables, and auxiliary lists. When a file was modified, the compiler had to check which function source bytes differed, and repeat AstGen for the changed functions to generate updated ZIR code.
One key design strategy is to make ZIR code immutable, typeless, and depend only on AST. This ensures that it can be re-used for multiple generic instantiations, comptime function calls, and inlined function calls.
This modification took that design strategy, and observed that it is possible to generate ZIR for an entire file indiscriminately, for all functions, depending on AST alone and not introducing any type checking. Furthermore, it observes that this allows implementing the following compile errors:
- Unused private function
- Unused local variable
- Unused private global variable
- Unreachable code
- Local variable not mutated
All of these compile errors are possible with AstGen alone, and do not require types. In fact, trying to implement these compile errors with types is problematic because of conditional compilation. But there is no conditional compilation with AstGen. Doing entire files at once would make it possible to have compile errors for unused private functions and globals.
With the way that ZIR is encoded, lowering all of a file into one piece of ZIR code is less overhead than splitting it by function. Less overhead of list capacity is wasted, and more strings in the string table will be shared.
{kind=link}
This works great for caching. All source files independently need to be converted to ZIR, and once converted to ZIR, the original source, token list, and AST node list are all no longer needed. The relevant bytes are stored directly in ZIR. So each .zig source file has exactly one corresponding ZIR bytecode. The caching strategy for this is dead simple. Consider also that the transformation from .zig to ZIR does not depend on the target options, or anything, other than the AST. So cached ZIR for std lib files and common used packages can be re-used between unrelated projects.
This made the first 3 phases of the compiler pipeline embarassingly parallel. Thanks to #2206, the compiler optimistically looks for all .zig source files in a project, and parallelizes each tokenize➡️parse➡️ZIR transformation. The caching system notices when .zig source files are unchanged, and loads the .ZIR code directly instead of the source, skipping tokenization, parsing, and AstGen entirely, on a per-file basis. The AST tree only needs to be loaded in order to report compile errors.
Because of the Reworked Memory Layout, serialization of ZIR in binary form is straightforward. It consists only of:
- List of u8 tags for each instruction
- List of u32, u32 data for each instruction
- List of u8 string table
- List of u32 auxiliary data
Writing/reading this to/from a file is trivial and is performed via a single writev/readv syscall, respectively.
Here is an example of using the new zig ast-check command to print how many bytes are used for one of the largest .zig files in the Standard Library:
$ zig ast-check -t std/os.zig | head -n7
# Source bytes: 238 KB
# Tokens: 35023 (171 KB)
# AST Nodes: 17397 (221 KB)
# Total ZIR bytes: 472 KB
# Instructions: 26586 (234 KB)
# String Table Bytes: 15.0 KB
# Extra Data Items: 57179 (223 KB)The key thing to remember here is that with "Total ZIR bytes" loaded in memory, the "Source bytes" remain on disk, never loaded into memory, and "Tokens", and "AST Nodes" are never computed. They only need to be loaded/computed for files which contain compile errors.
So although the .zig source code is pretty compact, if you add up "Source bytes", "Tokens", and "AST Nodes", it comes out to 630 KB, which is 1.3 times the number of "Total ZIR bytes". I checked the stats for all the std lib files, and found this 1.3 ratio to be extremely consistent.
This means that not only does whole-file AST lowering allow Zig to skip past 3 compiler phases for cached files, Zig ends up loading fewer bytes from disk in order to do so!
In this set of changes, I (Andrew) also reworked the incremental compilation infrastructure in the frontend, making it work cleanly with Standard Library integration. I made this infographic to communicate a sense of progress that this set of changes accomplished:
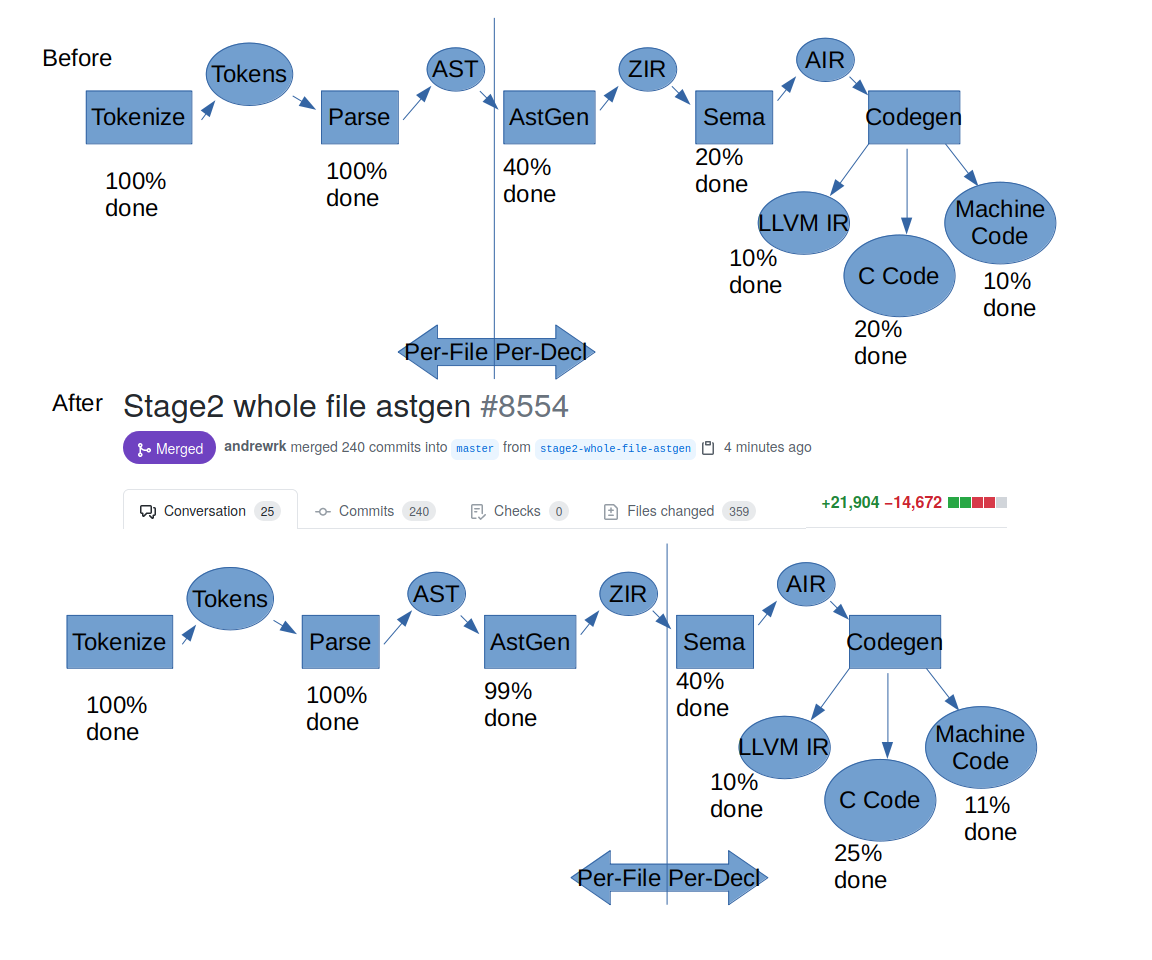
In order to have a proper benchmark to find out how fast the compiler is, we would need to have Sema (Semantic Analysis) complete (in the picture above, it is marked 40% done). However, we can at least collect a measurement for the first three phases of the pipeline and see how Zig is doing so far.
In summary, it comes out to 8.9 million lines per second on my 8-core i9-9980HK NVMe:
AstGen entire std lib, stage2 debug cold cache: 0m0.959s
AstGen entire std lib, stage2 debug warm cache: 0m0.066s
AstGen entire std lib, stage2 release cold cache: 0m0.033s
AstGen entire std lib, stage2 release warm cache: 0m0.018sThe lines-per-second number is derived by dividing how many lines of code are in the Standard Library (292,458) by the "release cold cache" number above (33ms)
There is no way Zig will be this fast when the implementation is completely finished. This number does not include the two final phases of the compiler pipeline. But these are some promising results so far! At least there is an upper limit to aim for.
zig ast-check command §
Thanks to this work, there is a new subcommand: zig ast-check
This command quickly reports a subset of compile errors (about 100 different things), without needing to know any information about the target or the build. This makes it suitable for automatic IDE integration, for quick turnaround on compile errors such as:
- Redeclaring the same variable name
- Redundant use of
comptime breakexpression outside loop- unused label
- returning from a
deferexpression
This command is also useful to Zig developers. It has a -t flag available
in debug builds of the compiler which renders the ZIR code into a textual format.
Here is an example:
hello.zig
const std = @import("std");
pub fn main() !void {
try std.io.getStdOut().writeAll("Hello, World!\n");
}$ ./zig ast-check -t hello.zig
# Source bytes: 109B
# Tokens: 32 (184B)
# AST Nodes: 16 (328B)
# Total ZIR bytes: 622B
# Instructions: 26 (234B)
# String Table Bytes: 48B
# Extra Data Items: 69 (276B)
%25 = extended(struct_decl(parent, Auto, {
[53] std line(0) hash(c9cf6ee7a5ad2804a9114568f721d663): %0 = block_inline({
%1 = import("std") token_offset:1:21
%2 = break_inline(%0, %1)
}) node_offset:1:1
[60] pub main line(2) hash(92a14e8c420ccc95ba5cac0402815cd9): %3 = block_inline({
%23 = func_inferred([], @Ref.void_type, inferror, {
%4 = dbg_stmt(1, 4)
%16 = block({
%5 = decl_ref("std") token_offset:4:9
%6 = field_val(%5, "io") node_offset:4:12
%7 = field_val(%6, "getStdOut") node_offset:4:15
%8 = call(%7, []) node_offset:4:25
%9 = field_val(%8, "writeAll") node_offset:4:27
%10 = param_type(%9, 0)
%11 = str("Hello, World!\n")
%12 = as_node(%10, %11) node_offset:4:37
%13 = call(%9, [%12]) node_offset:4:36
%14 = is_err(%13) node_offset:4:5
%15 = condbr(%14, {
%17 = err_union_code(%13) node_offset:4:5
%18 = ret_node(%17) node_offset:4:5
}, {
%19 = err_union_payload_unsafe(%13) node_offset:4:5
%20 = break(%16, %19)
}) node_offset:4:5
}) node_offset:4:5
%21 = ensure_result_used(%16) node_offset:4:5
%22 = ret_coerce(@Ref.void_value) token_offset:5:1
}) (lbrace=0:20,rbrace=2:0) node_offset:3:5
%24 = break_inline(%3, %23)
}) node_offset:3:5
}, {}, {})
Imports:
stdLTO §
LTO stands for Link Time Optimization. In summary, it means postponing the final stages of compilation and optimization until the very end, when all objects are available to examine at the same time.
The Command-Line Interface gains -flto and -fno-lto options to
override the default. However, the cool thing about this is that the defaults
are great! In general when you use build-exe in release mode, Zig will
enable LTO if it would work and it would help.
zig cc supports detecting and honoring the -flto
and -fno-lto flags as well.
This feature is implemented in a way that allows LLVM to optimize across the Zig and C/C++ code boundary:
main.zig
const std = @import("std");
export fn foo4() void {
_ = std.c.printf("Hi\n");
}
extern fn foo1() c_int;
pub fn main() u8 {
return @intCast(u8, foo1());
}a.c
int foo1(void);
void foo2(void);
void foo4(void);
static signed int i = 0;
void foo2(void) {
i = -1;
}
static int foo3() {
foo4();
return 10;
}
int foo1(void) {
int data = 0;
if (i < 0)
data = foo3();
data = data + 42;
return data;
}Output:
$ ./zig build-exe main.zig a.c -OReleaseFast -lc
$ ./main
$ echo $?
42
$ objdump -d main -Mintel | grep -A7 '<main'
0000000000201530 <main>:
201530: 48 c7 c0 ff ff ff ff mov rax,0xffffffffffffffff
201537: 66 0f 1f 84 00 00 00 nop WORD PTR [rax+rax*1+0x0]
20153e: 00 00
201540: 48 83 7c c2 08 00 cmp QWORD PTR [rdx+rax*8+0x8],0x0
201546: 48 8d 40 01 lea rax,[rax+0x1]
20154a: 75 f4 jne 201540 <main+0x10>
20154c: 48 63 cf movsxd rcx,edi
20154f: 48 89 35 7a 22 00 00 mov QWORD PTR [rip+0x227a],rsi # 2037d0 <argv>
201556: 48 89 0d 7b 22 00 00 mov QWORD PTR [rip+0x227b],rcx # 2037d8 <argv+0x8>
20155d: 48 89 15 7c 22 00 00 mov QWORD PTR [rip+0x227c],rdx # 2037e0 <environ.0>
201564: 48 89 05 7d 22 00 00 mov QWORD PTR [rip+0x227d],rax # 2037e8 <environ.0+0x8>
20156b: b8 2a 00 00 00 mov eax,0x2a
201570: c3 retThe interesting thing to note here is that there was no LTO explicitly opted into.
It happened automatically.
And you can see here that in the main function, there is no call to
foo1 and there is no exported foo4. If we didn't have LTO,
the call to foo1 could not have been inlined. For example, here's what
happens if we force-disable LTO:
$ ./zig build-exe main.zig a.c -OReleaseFast -lc -fno-lto
$ objdump -d main -Mintel | grep -A7 '<main'
00000000002015d0 <main>:
2015d0: 50 push rax
2015d1: 48 c7 c0 ff ff ff ff mov rax,0xffffffffffffffff
2015d8: 0f 1f 84 00 00 00 00 nop DWORD PTR [rax+rax*1+0x0]
2015df: 00
2015e0: 48 83 7c c2 08 00 cmp QWORD PTR [rdx+rax*8+0x8],0x0
2015e6: 48 8d 40 01 lea rax,[rax+0x1]
2015ea: 75 f4 jne 2015e0 <main+0x10>
2015ec: 48 63 cf movsxd rcx,edi
2015ef: 48 89 35 fa 22 00 00 mov QWORD PTR [rip+0x22fa],rsi # 2038f0 <argv>
2015f6: 48 89 0d fb 22 00 00 mov QWORD PTR [rip+0x22fb],rcx # 2038f8 <argv+0x8>
2015fd: 48 89 15 fc 22 00 00 mov QWORD PTR [rip+0x22fc],rdx # 203900 <environ.0>
201604: 48 89 05 fd 22 00 00 mov QWORD PTR [rip+0x22fd],rax # 203908 <environ.0+0x8>
20160b: e8 90 ff ff ff call 2015a0 <foo1>
201610: 0f b6 c0 movzx eax,alNow you can see Zig is forced to call foo and return its result.
Tracking issue: #2845
Static PIE §
Mainly thanks to LemonBoy, Zig now supports Position Independent Executables, even when compiling statically. Here is an example:
$ zig build-exe hello.zig $ file hello hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, with debug_info, not stripped $ zig build-exe hello.zig -fPIE $ file hello hello: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, with debug_info, not stripped
The main use case for PIE is Address Space Layout Randomization. This is a security measure aimed at making exploits more difficult by introducing non-determinism into pointer addresses at runtime. Its effectiveness is debatable, however, it also has a surprisingly useful property.
It is one piece of the puzzle in a truly portable Linux binary that can run on any distribution, including loading graphics drivers. A static PIE is capable of executing both statically linked, and then re-executing itself dynamically linked once the statically linked code has surveyed the system to find the dynamic linker. This is a niche idea, but may be worth pursuing for the use case of distributing portable game binaries and other GUI applications.
Native libc Integration §
Thanks to an improvement by Isaac Freund, Zig will now integrate with system libc when targeting the native OS/ABI and linking any system libraries.
Before, Zig would always try to build its own libc and compile against that. This of course makes sense for cross-compilation, but can cause problems when targeting the native OS/ABI, when combined with other system libraries.
For example, if the system uses a newer glibc version than zig ships, zig will fall back to using the newest version it does ship. However this causes linking system libraries to fail as they are built against a different glibc version than the zig code is built against.
On the other hand, if not linking system libraries, using the zig-provided libc is more reliable as it does not depend on any quirks of the host system or being able to invoke the system C compiler to find include directories.
Reuse Runtime Libraries in More Cases §
Previously Zig would need to recompile runtime libraries if you changed the
values of --strip or -O. Now, unless the debug_compiler_runtime_libs
flag is set (which is currently not exposed to the CLI), Zig will always
choose ReleaseFast or ReleaseSmall for compiler runtime libraries.
When the main application chooses ReleaseFast or ReleaseSmall, that value is propagated to compiler runtime libraries. Otherwise a decision is made based on the target, which is currently ReleaseSmall for freestanding WebAssembly and ReleaseFast for everything else.
Ultimately the purpose of this change is to have Debug and ReleaseSafe builds of applications still get optimized builds of, e.g. libcxx and libunwind, as well as to spend less time unnecessarily rebuilding compiler runtime libraries.
x86-64 Backend §
- Use ABI size to determine 64-bit operation.
- Implement integer multiplication.
- Encoding helpers to make future contributions easier.
See the set of test cases passing for x86-64
Contributors: gracefu, Joachim Schmidt
AArch64 Backend §
The experimental self-hosted AArch64 (a.k.a. ARM64) backend is new in this version. Currently, the self-hosted compiler is able to generate binaries for Linux (ELF) and macOS (Mach-O, thanks to Jakub Konka). Currently, only a very small subset of the Zig language is supported.
See the set of test cases passing for aarch64
ARM Backend §
Bitwise operations on and multiplication of 32-bit integers were introduced. Furthermore, conditional branching (including while- and for-loops) is now possible. Additionally, the register allocation mechanism was overhauled, allowing for correct code generation in situations where registers are spilled.
See the set of test cases passing for ARM
Contributors: Joachim Schmidt
LLVM Backend §
Timon Kruiper broke ground on the stage2 LLVM backend during this release cycle.
See the set of test cases passing for the LLVM backend
WebAssembly Backend §
This is a work-in-progress backend newly introduced in 0.8.0.
During the self-hosted compiler meeting of 2020-12-10 we discussed on how to move forward with the architecture of the backends. A proof of concept was done in #7321 to merge it with the other backends. However, it was found to be counter intuitive and ultimately decided upon to keep the wasm backend seperately.
Apart from this design decision, progress was made to bring up the wasm backend closer towards feature completeness:
- Implement storing and loading of locals (#7726)
- Refactoring the wasm backend to streamline its implementation with the other backends. (#7797)
- Support for control flow such as while loops and if statements. (#7895)
- Importing and calling of extern functions. Allowing to call host functions from within Zig. (#7960)
- Unary operator '!' support. (#8339)
- Opcode builder and multiple binary operands implemented. (#8416)
- "Hello world" support (arrays and pointer to arrays). (#8439)
- Enums (#8789)
- Initial implementation of structs and switches. (#8847)
- Support for error sets and error unions. (#8923)
See the set of test cases passing for the WASM backend
Contributors: Luuk de Gram, Isaac Freund, gracefu
RISC-V 64 Backend §
This is a work-in-progress backend newly introduced in 0.8.0.
See the set of test cases passing for the RISC-V 64 backend
Contributors: Joachim Schmidt
C Backend §
- Added tests for emit-h functionality.
- Implemented
@breakpoint. - Improved test harness to support executing generated C code.
- Proper integration with incremental compilation of the frontend.
- condbr, breaks, switchbr, not, bitwise ops, optionals, errors
- Numerous other sweeping changes.
See the set of test cases passing for the C backend
Contributors: Andrew Kelley, Veikka Tuominen, Jacob G-W, Noam Preil, Alex Cameron, Tadeo Kondrak
SPIR-V Backend §
Robin Voetter broke ground on the SPIR-V backend during this cycle. It's not yet to the point where we can get a "hello world" vulkan triangle, but the skeleton of the backend is in place. There are quite a few language issues to overcome. This backend challenges the ability for Zig to be true to its "general-purpose" claim, and it is a welcome challenge! The existence of this backend will help shape the Zig language specification and prevent it from being overfitted to x86-like ISAs.
SPU Mark II Backend §
This backend, related to the Ashet Home Computer project, was incomplete, and the maintainer stopped working on it. Since it never made it to a usable state, this backend is removed in 0.8.0.
The code is still safely stored in the Git history, and anyone is welcome to revive it!
Miscellaneous stage2 Improvements §
- Default AVR generic cpu to avr2
- parser: Use an operator precedence table
- parser: use shared scratch buffer to avoid allocating and freeing many small lists (#8910).
- Update the official spec to match the self-hosted parser.
- tokenizer: fix crash on multiline string with only 1 backslash (#8904).
- Variable shadowing detection (#6969).
- link: properly implement passthrough mode for LLD child proccess.
- Detect redundant C/C++ source files, preventing a deadlock in the caching system (#7308).
- Print package path on --pkg-begin failure.
- Better error message for root zig source file not found (#6777, #6893).
- Always link -lpthread when using system libc. Required when cross-compiling glibc targets.
- Fix libc components' linking order.
- Add support for
-mred-zoneand-mno-red-zone - Ability to build stage1 using only a zig tarball.
Contributors: Andrew Kelley, Jakub Konka, Veikka Tuominen, joachimschmidt557, Evan Haas, Isaac Freund, Jacob G-W, LemonBoy, Timon Kruiper, gracefu, Alex Cameron, xackus, Michael Dusan, Tadeo Kondrak, Alexandros Naskos, Noam Preil, g-w1, xavier, Ersikan, Jay Petacat, Robin Voetter, antlilja, daurnimator, Asherah Connor, Dimenus, Guoxin Yin, Jonathan Marler, Lee Cannon, Luuk de Gram, Josh Holland, Koakuma, Mitchell Kember, Rafael Ristovski, Ryan Liptak, Sizhe Zhao, Sreehari S, lithdew, protty, tgschultz
Self-Hosted Linker §
As you may know from our previous releases, we had immense problems with
ld64.lld linker on macOS - it is subpar in functionality to other target
formats (Elf, Coff, etc.) and it does not support the latest arm64-based Macs
(see #7527 or #3295 for some of the issues we encountered). While there has been
progress on the new lld's MachO backend dubbed ld64.lld.darwinnew,
it is still not the default backend as of LLVM 12. Additionally, it is
doubtful that the new backend will allow for seamless cross-compilation to macOS
since every macOS binary is required to be a PIE and link dynamically against
libSystem dylib, which will require the lib's presence on the host
for the lld to reference and link against.
These were enough to make a case for building our own linker, written entirely in Zig, which would initially focus on MachO linking. Since our core team member, Jakub, has already been working on the stage2 MachO backend before, he decided to try his luck at writing a traditional MachO linker in Zig from scratch which he started towards the end of January 2021. Fast forward a couple of months, and since May 2021, we are incredibly happy to report it is used as our primary linker when targeting macOS and is successfully able to link the stage1 Zig compiler as part of the zig-bootstrap effort (see ziglang/zig-bootstrap#38 and ziglang/zig-bootstrap#44).
This means Zig can be used to successfully cross-compile C/C++ (clang) and Zig to macOS from anywhere!
In summary, cross-compiling C/C++ and Zig to macOS is now as trivial as adding
-target aarch64-macos or -target x86_64-macos to the invocation
of your chosen Zig tool (zig cc, zig c++, or zig build-exe).
There are still bits of functionality that are missing such as the ability to create a
dynamic library or
linking against text-based definitions (.tbds)
but Jakub plans to address these next.
In celebration of Jakub's recent accomplishments of improving the self-hosted linker on Mach-O enough to be able to link LLVM, Clang, LLD, and Zig, we now have the tracking issue Completely Eliminate Dependency on LLD with the goal of eventually completely relying on our own linker implementation for all targets, and entirely stop linking against LLD.
This issue does not block the release of Zig 1.0, however it is a stretch goal, and a fun indicator of progress to keep track of along the way.
Here are all the places we depend on LLD, along with an indicator of how much our own linker code can do:
- 🟡 ELF:
- 🟡 x86, x86_64
- 🟡 arm, aarch64
- 🟡 riscv
- 🔴 hexagon
- 🔴 mips
- 🔴 ppc, ppc32
- 🔴 sparc
- 🔴 amdgpu
- 🔴 avr
- 🔴 msp430
- 🟢 Mach-O
- 🟢 x86_64
- 🟢 aarch64
- 🟡 COFF/PE
- 🟡 x86, x86_64
- 🔴 arm, aarch64
- 🟡 WASM
Key:
- 🟢 major progress
- 🟡 some progress
- 🔴 no progress
Another issue to note here is that this release does not include a drop-in
linker sub-command, e.g. zig ld. At this time Zig is lacking the glue
code to hook up the Command-Line Interface to the linker implementation.
If you are interested in this use case, the tracking issue is
zig ld: a drop-in linker replacement.
C Translation §
This is the feature that powers both zig translate-c as well as
@cImport syntax. It is implemented in the Self-Hosted Compiler,
using the libclang C++ API.
This release cycle saw a prolific new contributor to this area of the code - Evan Haas. Not only did he contribute many improvements to C translation this cycle, but his company, Lager Data, sponsors Zig. What a guy!
Vexu implemented a major simplification of the implementation of translate-c by introducing a new pseudo-ast data structure. Instead of the code having to manage both AST nodes and tokens at once, in order to render the output Zig code, now the C translation code only must create pesudo-AST nodes, which are then lowered to tokens at the end. This made the code easier to maintain and contribute to, and greatly simplified the Reworked Memory Layout efforts that happened simultaneously in the Self-Hosted-Compiler.
Miscellaneous improvements:
- Added support for translating FnDecl's that appear within functions.
- Added support for __cleanup__ attribute, using a
deferstatement to implement the C __cleanup__ attribute. - Demote initialization of opaque types. Fixes a segfault in translate-c that would previously occur when initializing structs with unnamed bitfields.
- Added support for translating global (file scope) assembly.
- Fixed typedefs with multiple names.
- Fixed casting of function pointers.
- Group field access LHS if necessary and LHS of array access if necessary.
- Better handling of int to enum casts (#6011).
- Wrap switch statements in a
while (true)loop. This allowsbreakstatements to be directly translated from the original C (#8387). - Added support for vector expressions, including vector types, __builtin_shufflevector, and __builtin_convertvector.
- Fix calls with no args in macros.
- intcast compound assignment operand if different-sized integer.
- Stop creating unnamed decls for typedefs child types.
- Ensure assignments are within a block when necessary (#8159).
- Preserve zero fractional part in float literals.
- Use
[N:0]arrays when initializer is a string literal (#8264, #8215). - Demoted usage of un-implemented builtins.
- Implemented generic selection expressions. Enables translation of C code that uses the
_Generickeyword. - Added compound literal support.
- Explicitly cast decayed array to pointer with
@ptrCast. This enables translation of code that uses pointer arithmetic with arrays. - Support compound assignment of pointer and signed int.
- Translate align attribute for block scoped variables.
- Strip the leading zero from octal literals.
- Enable pointer arithmetic with signed integer operand.
- Added <assert.h> support.
- Added limited OffsetOfExpr support.
- Added typeof support.
- Added support for pointer subtraction (#7216).
- Check for noreturn in switch in more cases.
- Made switch default have an empty block not break.
- Use global scope for typedef/record/enum type translation if needed.
- Correctly add semicolon to if statements.
- Ensure failed macros don't get defined multiple times.
- Improved switch translation.
- Support scoped typedef, enum and record decls (#5256).
- Demote untranslatable declarations to externs.
- Elide some unecessary casts of literals.
- Made comma operator introduce a new scope, preventing inadvertent side-effects when an expression is not evaluated due to boolean short-circuiting (#7989).
- Call
@boolToInton return value when necessary (#6215). - Improve function pointer handling (#4124).
- Added wide string literal support.
- Fixed bug when rendering struct initializer with length 1.
- Improved array support (#4831, #7832, #7842).
- Added Wide, UTF-16, and UTF-32 character literals.
- Ensure bools are cast to int when necessary.
- Allow dollar sign $ in identifiers (#7585).
- Static function declarations with no prototype should not be variadic (#7594).
- Demote variadic functions to declarations.
- Correctly cast bool to signed int.
- Improve handling of C compiler intrinsics (#6707).
- Detect parenthesized string literals.
- Support casting enums to all int types.
Here's a fun example, translating one of the many files of DOOM to Zig, and then compiling the resulting Zig code into an object:
andy@ark ~/D/D/linuxdoom-1.10 (master)> zig translate-c -lc m_cheat.c >m_cheat.zig andy@ark ~/D/D/linuxdoom-1.10 (master)> zig build-obj m_cheat.zig andy@ark ~/D/D/linuxdoom-1.10 (master)> file m_cheat.o m_cheat.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), with debug_info, not stripped
This is one of the smaller C files; I ran into quite a few opportunities for more C translation improvements when looking for this example!
Contributors: Evan Haas, Veikka Tuominen (Vexu), xackus, Andrew Kelley, LemonBoy, Isaac Freund, Michael Dusan, Tadeo Kondrak, Timon Kruiper
Standard Library §
The Zig standard library is still unstable and mainly serves as a testbed for the language. After the Self-Hosted Compiler is completed, the language stabilized, and Package Manager completed, then it will be time to start working on stabilizing the standard library. Until then, experimentation and breakage without warning is allowed.
Miscellaneous Improvements:
- json: option to ignore unknown fields (#7906)
- make writeIntSlice functions work for signed integers
- os: munmap takes a const pointer
- fix Boyer-Moore-Horspool algorithm in indexOfPos and lastIndexOf when element type is larger than a byte
- fix accidental quadratic dependence on haystack length in replace and replacementSize (#8859)
- Const correct GUID parameter of getInfo and setInfo
- os: WSAStartup is now called upon socket creation when needed
- Make atfork handler more robust (#8841).
- Call pthread_atfork only once
- add android __SIZEOF_PTHREAD_MUTEX_T (#8384)
- math.Complex: Change new() to init()
- add missing EBADF error code for openat
- Avoid using white color when printing stacktraces. Use .bold instead of .white, the effect is the same for light-on-dark terminals but greatly improves the readability for dark-on-light ones (#8761).
- dragonfly: fix duplicate definition of sockaddr_storage
- rework math.scalbn (#8733)
- hash_map: use 7 bits of metadata instead of 6
- compiler-rt: Fix signedness mismatch in f128 mul impl
- dragonfly: fix duplicate definition of sockaddr_storage
- fix logic for duplicate comptime fields and avoid freeing comptime fields in parseFree and parseInternal
- fix duplicate_field_behavior UseFirst in json.zig
- json: Fix premature closing brace being considered valid JSON
- fix shrinkAndFree and remove shrinkRetainingCapacity in PriorityQueue and PriorityDequeue
- mem: add sliceTo(), deprecate spanZ(), lenZ()
- bsd: detect os version
- meta.Elem: support all optional types
- Fix offset param splitting for preadv/pwritev
- Harmonize use of off_t between libc and Zig impls
- c: Fix prototypes for bcmp and memcmp
- Prefer 64bit libc functions where possible
- os: add missing sockaddr_storage defs
- os: fix sockaddr_storage padding size
- ArrayList: add clearRetainingCapacity and clearAndFree
- Implement hex float printing
- compiler-rt: Better selection of __clzsi implementation
- Accept unaligned slice in several ArrayListAligned ops. Do not impose the internal alignment requirements to the user-supplied parameters (#8647).
- GeneralPurposeAllocator: print leaked memory addresses. This helps when using it with other tools, such as memory watchpoints.
- handle -frandom-seed in NIX_CFLAGS_COMPILE
- Implement copysign, signbit, isFinite for f128
- rename doc refs to deprecated functions like openC (#8467)
- Improve spinloop hint
- Handle EPERM and ELOOP in os.fstatat()
- remove redundant `comptime const`
- Add a parser for hexadecimal floating point numbers
- Target: bump freebsd known maximum version
- thread: simplify and remove useless return in spawn (#8621)
- Fix for mem.replacementSize adjacent matches bug. (#8454, #8455)
- Fix thread creation with field-less context type (#8524).
- Make meta.alignment work on more types
- compiler-rt: Export __extendhftf2 and __trunctfhf2
- Use stat definition with 32bit *time fields. We're not ready for Y38K yet.
- Split syscall parameters for PowerPC targets
- macho: fix typos in consts defs
- c: Implement fmax and fmaxf
- c: Implement fmin and fminf
- Add process_vm_readv/writev wrappers
- deprecate ensureCapacity, add two other capacity functions
- Add pidfd wrappers
- linux: fix number of arguments for tgkill syscall
- change `@import("builtin")` to `std.builtin`
- compiler-rt: Don't pass f16 around as arguments
- compiler-rt: Implement __trunctfhf2
- compiler-rt: Implement __extendhftf2
- compiler-rt: Fix typo in implementation of fp truncation ops
- os/posix: handle ECONNRESET for write/writev
- Fix sqrt for u0/u1 input types
- dwarf: fix LineNumberProgram check (#8421).
- compiler-rt: Introduce PowerPC-specific f128 helpers
- Fix TLS definitions for 32bit PowerPC targets
- Improve powerpc support.
- netbsd: minor fixes to allow stage1 to build
- os/linux: return error on EALREADY for connect() and getsockoptError()
- os/bits/linux: add IPv6 socket options
- Switch json to use an ordered hashmap
- Add compile error for signed integer math. Output compile errors when signed integer types are used on functions where the answer might've been a complex number but that functionality hasn't been implemented. This applies to sqrt, log, log2, log10 and ln.
- os: handle ECONNRESET for connect() syscall
- base64: cleanups and support url-safe and other non-padded variants
- os.linux: handle ECONNRESET for recv
- UEFI: boot_services: implement locateDevicePath
- Specify type in autoHash error message (#7970).
- Add reset to TokenIterator
- Add syscall7 stub for Linux/MIPS
- Add some enum utilities
- support optional getaddrinfo arguments
- linux: sync io_uring library with liburing
- make c.getErrno() return same type as _errno() aka c_int
- elf: make EM non-exhaustive
- expose machine field in ELF header
- Implement fmtDuration using Formatter (#8137)
- Prevent null pointer deref in mem.len{,Z} (#8140).
- Reject bare +/- input when parsing floats
- add io.Writer.writeStruct
- linux: fix IO_Uring.timeout
- Replace lastIndexOf with lastIndexOfScalar
- Add fs.path.joinZ (#7974)
- add sendmsg
- Swap arguments in Thread.spawn (#8082).
- Target.Abi: add gnuilp32
- ascii: add lessThanIgnoreCase and orderIgnoreCase
- Thread.Semaphore: Fix wrong variable name (#8052).
- fifo.LinearFifo - Expose reader and writer type.
- os.uefi.Guid fixes (#8032)
- fix race condition in linuxWaitFd
- Progress: improve support for "dumb" terminals
- replace ArrayList.shrinkAndFree by ArrayList.shrinkRetainingCapacity
- Add epoll_pwait2 Linux syscall
- remove io.AutoIndentingStream
- fs.net.Stream: add writev and writevAll
- json: large number support
- Don't read more bytes than exist in MsfStream (#7839)
- Fixes for Thread.Condition (#7883)
- math.big.int: normalize after a right shift
- json: support for comptime fields (#6231).
- Remove
@TagType;meta.TagTypetometa.Tag(#7750). - GeneralPurposeAllocator: logging improvements
- meta: rename TagPayloadType to TagPayload
- meta: rename TagType to Tag
- Fill out more cases for meta.sizeof
- Fix interger overflow when calling joinZ with empty slices
- macho: add arm64 relocation type enum
- Add MAX_RW_COUNT limit to os.pread() (#7805).
- linux: add fallocate() to io_uring
- Change
compareFntofn (a: T, b: T) math.Order - Add missing cast when calling fcntl w/ constant args
- Fixed pipe2 fallback (#7760)
- Replace
shrinkwithshrinkAndFreeandshrinkRetainingCapacity - Add Priority Dequeue
- Organize std lib concurrency primitives and add RwLock
- elf: expose parsing decoupled from fs.File
- os.uefi.protocols.FileProtocol: fix and expose get_position, set_position (#7762)
- Add missing ECONNRESET from getsockoptError
- implement emutls in compiler_rt
- event.Loop: fix race condition when starting the time wheel (#7572).
- Add fmt.formatDuration and fmt.duration (#7297)
- Made reader.skipBytes's num_bytes a u64
- os/bits/linux: add the termios cc bits
- Modify cityhash to work at comptime
- Decouple network streams from fs.File
- Update path.join to recognize any separators that isSep does
- debug: don't fail printLineInfo if the source file is not readable
- builtin: Add zig_version (#6466)
- Fix system library path detection on Linux.
- Add mem.containsAtLeast
- io:
FindByteOutStreamtoFindByteWriter(#4917). - Add EPERM to os.setsockopt
- Add IP_ constants
- fix LRESULT and LPARAM typedefs
- spinlock: Default SpinLock.state to .Unlocked to allow default struct initialization
- c: add syslog
- freebsd, netbsd, dragonfly: add struct timeval
- Rename ArrayList shrink to shrinkAndFree
- c: add some noalias
- meta.fieldInfo takes an enum rather than a string
- Add meta.FieldEnum
- Show the panicking thread ID
- Add more standard type definitions for FreeBSD (#7550).
- Fix Reader.readUntilDelimiterOrEofAlloc() API
- Uniform polling logic for Windows and Unix.
- Fixed fs.Watch implementation on Linux and Windows
- Fix poll definitions for FreeBSD/Darwin
- Avoid deadlocking in ChildProcess.exec.
- zig test: testing.zig_exe_path is now available. It will be set to the path of the zig executable which is running `zig test`.
- Add c._exit() and use in ChildProcess
- Made hasUniqueRepresentation false for slices; handle unions in autoHash
- Rework ResetEvent, improve std lib Darwin integration
- ResetEvent: use sem_t when linking against pthreads
- Mutex: integrate with pthreads
- Add termios bits for darwin
- c: add fmemopen
- Add sincosf function (#7267)
- Truncate user and group ids for 64 bit Linux systems (#7466)
- Enable segfault handling on FreeBSD.
- Fix Gimli hash on 16n byte inputs
- Add io.counting_reader
- Cast sendto to SendError inside send (#7481)
- Progress: make the API thread-safe
- Add EV_ERROR to FreeBSD bits
- Add Linux baudrate constants
- Add process_madvise to Linux syscalls (#7450)
- Prevent hashing undefined bits for integers of non power of 2 size.
- Create SendToError (#7417)
- non-byte-multiple sized integers and bool have no definite representation (#7445).
- Add missing Linux syscalls.
- Fix formatting of type values (#7429).
- Improve sigaction interface (#7411)
- CrossTarget: add isNativeAbi()
- Make json.unescapeString pub.
- Validate the atomic ordering parameter in atomic.Int
- Prevent instantiation of atomic.Int with non-integral types
- Introduce meta.traits.is{Integral,Float}
- MoveFileEx can return ACCESS_DENIED.
- Add io_uring TIMEOUT and TIMEOUT_REMOVE operations.
- explicitly cast indices to usize. This is needed for platforms where usize=u16, eg. MSP430.
- compiler-rt: Fix compilation of clzsi for armv6 targets
- compiler-rt: Avoid exposing atomic builtins when not supported
- Add testing.expectStringEndsWith
- Fix general purpose allocator incorrectly modifying total_requested_bytes in some cases
- Add AddressFamilyNotSupported to SendError
- c: freeing null is a no-op
- Add a few helpers for matching ascii strings (#7300)
- Make the mutex for GeneralPurposeAllocator configurable (#7234).
- Add readUntilDelimiterOrEofArrayList and readUntilDelimiterOrEofAlloc.
- Make the use of pthread_join POSIX-compliant (#7275)
- Always return loopback address when looking up localhost.
- os: remove unneeded error from accept errorset.
- add os.shutdown function for sockets
- Fix memory leak in BufMap.
- meta: add assumeSentinel
- Avoid deadlock in the signal handler (#7247).
- Add readAllArrayListAligned to Reader which can accept an arbitrary alignment
- Fix file locking logic for BSD targets
- os: fix prctl constants
- use mem.asBytes in Ip4Address.parse so it works at comptime.
- Close dangling fd on error.
- Remove O_NONBLOCK flag after locking. We only need O_NONBLOCK when O_SHLOCK/O_EXLOCK are used and we don't want open() to block, don't let this bit leak to the user fd.
- Fix file locking logic for BSD targets.
- Fix the ELF base calculation.
- Fix logic for detecting _DYNAMIC symbol.
- user32 cleanup, added wrappers and additional functions.
- Add support for ppoll
- os: add time_t and dev_t definitions for x86_64 linux.
- meta.declarations: support
opaque {} - Add builtin.Signedness, use it instead of is_signed
- getdents: entries with d_ino==0 are now properly skipped
- Change seed for Murmur2_64 from u32 to u64.
- Add atomic.Bool and expose all atomic operations from atomic.Int (#7154).
- Add meta.fieldNames.
- Add fs.openDirAbsolute and fs.accessAbsolute (#7082)
- Move leb128 out of debug and remove trivial *mem functions as discussed in #5588 (#6876)
- linuxWaitFd: make NetworkSubsystemFailed error unreachable. This error from os.poll is Windows-specific, so unreachable on Linux.
- Add more MachO consts and structs.
- mem: make sliceAsBytes, etc. respect volatile
- Add fs.path.extension.
- Improved support for OpenBSD.
- Fix json parser close tracking (#6865).
- Don't prevent compilation on platforms where debug info is unsupported
- Add
mem.timingSafeEql()for constant-time array comparison. - ArrayList.span is now a compile error. Instead, use the
itemsfield directly. - Add unicode.utf8CountCodepoints and unicode.utf8ValidCodepoint
- start code:: export main with strong linkage. Unmarks `_main` as weak symbol making it global (the entire linked program) in scope.
- start code: increases stack size as appropriate on linux (#8708).
- start code: unconditionally import the root source file
- start code: call wWinMain with root's type.
- start code: make more versatile by always aligning the entry point.
- start code: properly align thread local variables. They were landmines if LLVM decided to optimize any writes to them using vector instructions.
- Make C allocator respect the required alignment. Uses posix_memalign where
available and the _aligned_{malloc,free} API on Windows (#3783). The new
heap.raw_c_allocator is available to do what
heap.c_allocatorpreviously did. See the new doc comments for more details. - Made
Version.parseless strict. - Added
LinearFifo(...).pump(src_reader, dest_writer)
Contributors: Andrew Kelley, LemonBoy, Isaac Freund, Jakub Konka, lithdew, daurnimator, Frank Denis, Veikka Tuominen, Sébastien Marie, xackus, Michael Dusan, Matthew Borkowski, Jonathan Marler, Zander Khan, Asherah Connor, Koakuma, Vincent Rischmann, Alexandros Naskos, Rohlem, Al Hoang, Tadeo Kondrak, Vexu, Evan Haas, Lee Cannon, Martin Wickham, Jacob G-W, Felix (xq) Queißner, Kenta Iwasaki, Robin Voetter, Benjamin Feng, Jay Petacat, Joran Dirk Greef, Luuk de Gram, data-man, Alex Cameron, Hubert Jasudowicz, Julius Putra Tanu Setiaji, Loris Cro, Rocknest, Timon Kruiper, Aransentin, Bill Nagel, Jonathan Knezek, Lewis Gaul, antlilja, rgreenblatt, viri, Asherah Connor, Cameron Conn, Dmitry Atamanov, Isaac Yonemoto, Jens Goldberg, Josh Holland, Lewis Gaul, Ryan Liptak, Sage Hane, Shachaf Ben-Kiki, Sobeston, Sreehari S, Tau, frmdstryr, luna, root, ryuukk, tgschultz, Adam Goertz, Aiz672, Anders Conbere, Andreas Karlsson, Andreas Linz, Benjamin Graf, BinaryWarlock, Bxil, Carlos Zúñiga, Daniele Cocca, Devin Bayer, Edward Dean, Ethan Gruffudd, Guillaume Ballet, Hadron67, Hannu Hartikainen, J.C. Moyer, Joris Hartog, Josh Wolfe, Julian Maingot, Kenta Iwasaki, Lewis Gaul, Luna, Maciej Walczak, Mahdi Khanalizadeh, Manuel Floruß, Mathieu Guay-Paquet, Matt Knight, Matt Sicker, Meghan Denny, Michael Freundorfer, Michael Holmes, Miles Alan, Nathanaël Courant, Nuno Leiria, Rageoholic, Ryan Greenblatt, Sahnvour, Travis, Yorhel, ZapAnton, aiz, breakin, christian-stephen, cryptocode, ducdetronquito, fancl20, gracefu, heidezomp, johnLate, jumpnbrownweasel, mason1920, protty, viri, Žiga Željko
Formatted Printing §
- Added 'u' specifier.
- Implemented named arguments and runtime width/precision.
- Reworked the whole parser.
- Removed z/Z format specifiers. Instead, use std.zig.fmtId.
- Fixed the `*` specifier for more types, print an error message if we can't show the value address.
- Disable the special casing of {} for u8 slices/arrays. Unless {s} is specified the contents won't be treated as a string.
- Improved error messages in std.fmt (#7898)
- Introduce {'} to indicate escape for a single-quoted string, and {} to indicate escape for a double quoted string.
- Removed 'x'/'X'/'e'/'E' special cases for u8 slices. Instead use fmt.fmtSliceHexLower and fmtSliceHexUpper.
- Removed the B and Bi format specifiers. Instead use fmt.fmtIntSizeDec and fmtIntSizeBin.
fs.path.dirname: return null when input path is root §
dirname.zig
const std = @import("std");
test "dirname on root path" {
try std.testing.expect(std.fs.path.dirname("/") == null);
}$ zig test dirname.zig
Test [1/1] test "dirname on root path"...
All 1 tests passed.
This intentionally diverges from the unix dirname command, as well as Python and Node.js standard libraries, which all have this edge case return the input path, unmodified. This is a footgun, and nobody should have ever done it this way.
Even the man page contradicts the behavior. It says: "strip last component from file name". Now consider, if you remove the last item from an array of length 1, then you have now an array of length 0. After you strip the last component, there should be no components remaining. Clearly, returning the input parameter unmodified in this case does not match the documented behavior. This is my justification for taking a stand on this API design.
Fixes #6746, #6727, #6584, #6592, #6602
Thread-Local CSPRNG for General Use §
std.crypto.random is now available. It is an implementation
of the std.rand.Random interface (#6704):
test.zig
const std = @import("std");
pub fn main() !void {
var bytes: [10]u8 = undefined;
std.crypto.random.bytes(&bytes);
const boolean = std.crypto.random.boolean();
const int = std.crypto.random.uintLessThan(u8, 100);
std.debug.print("bytes: {x}\nboolean: {}\nint: {d}\n", .{
std.fmt.fmtSliceHexLower(&bytes), boolean, int,
});
}$ zig build-exe test.zig
$ ./test
bytes: 40cf6092494dfcc6f437
boolean: false
int: 98
std.crypto.randomBytes is
removed in favor of std.crypto.random.bytes.
Some details about this implementation:
- It is cross platform, even freestanding.
- It cannot fail. On initialization for some systems requires calling
os.getrandom(), in which case there are rare but theoretically possible errors. The code panics in these cases, however the application may choose to override the default seed function and then handle the failure another way. - It is thread-safe.
- The randomness is cryptographically secure.
- It calls arc4random on systems that support it.
- On Linux, AT_RANDOM is ignored and not used to seed it.
- On Linux, MADV_WIPEONFORK is used to provide fork safety.
- On pthread systems, `pthread_atfork` is used to provide fork safety.
- For systems that do not have the capability to provide fork safety, the implementation falls back to calling getrandom() every time.
- If madvise is unavailable or returns an error, or pthread_atfork fails for whatever reason, it falls back to calling getrandom() every time.
- Applications may choose to opt-out of fork safety.
- Applications may choose to opt-in to unconditionally calling getrandom() for every call to std.crypto.random.fillFn.
Thanks to LemonBoy for finding and fixing a flaw in the use of madvise (#7609).
Crypto §
Legacy Keccak hash functions §
The legacy Keccak hash functions have been added (hash.sha3.Keccak_256, hash.sha3.Keccak_512). They only differ from the standard SHA-3 functions by their domain separation byte.
These functions are not recommended as they are slow and non-standard. However, popular blockchains such as Ethereum still require them.
AES-OCB §
This release adds AES-OCB, which has been around for a long time. It's simpler, faster and has better nonce-reuse resistance than AES-GCM.
RFC 7253 was published in 2014. OCB also won the CAESAR competition along with AEGIS that we already had.
So, why isn't everybody using it instead of GCM? And why didn't we have it in Zig before?
The sad reason for this was patents. GCM was invented only to work around these patents, and for all this time, OCB was that nice thing that everybody knew existed but that couldn't be freely used.
That just changed in February 2021. The OCB patents have been abandoned, and OCB is now public domain.
ISAP §
We already had ciphers optimized for performance, for compatibility, for size and for specific CPUs.
However we used to lack a class of ciphers that is becoming increasingly important, as Zig is being used for embedded systems, but also as hardware-level side channels keep being discovered.
Please welcome ISAPv2 (ISAP-A-128a), a cipher specifically designed for resilience against leakage and fault attacks.
ISAPv2 is not fast, but can be an option for highly sensitive data, when the runtime environment cannot be trusted.
Hash-To-Curve §
Is there a way to map an arbitrary string into an elliptic curve point, so that the discrete log is not known?
While more and more protocols require such a function, there was no standard way to do it until the hash-to-curve specification came out.
This release adds crypto.ecc.Edwards25519.fromString(), implementing the suites defined in the specification for the Edwards25519 curve.
Double-Base Scalar Multiplication §
Signatures systems over elliptic curves frequently require computing Px+Qy, with P and Q being different points on the same curve.
And a specialized function can be much faster than computing both multiplications separately.
Incidentally, this is exactly what the new Edwards25519.mulDoubleBasePublic() and P256.mulDoubleBasePublic() functions do.
P-256 §
They were invented by a US government agency. They are prone to side channels. Secure or not, implementations tend to be slow. Renowned cryptographers don't trust them much. And Zig already includes better alternatives such as Ristretto255.
But the NIST curves are deployed everywhere. Far more than any other curves. For compliance reasons or simply because most protocols don't support anything else, we need them.
Zig 0.8.0 adds support for the NIST P-256 curve. Other prime-order curves will follow shortly.
Since they don't use "nice" primes, safely implementing finite field arithmetic for these curves is tricky, and many implementations got hit by carry propagation bugs.
We took the approach of contributing a Zig backend to fiat-crypto, a project to generate arithmetic that has been formally proven for correctness.
The output of that tool is the core of our P-256 implementation, making Zig the first general-purpose language with formally verified cryptography right in the standard library. Support for other curves will be done the same way.
Please note however, that verification stops at source-level, and doesn't protect against possible compiler bugs.
Constant-Time Comparisons §
A new function was added to compare (not just for equality) byte strings: crypto.utils.timingSafeCompare().
It is useful to compare arbitrary-large nonces, counters or serialized field elements.
Round-Reduced ChaCha20 §
Round-reduced versions (8 and 12 rounds) of the ChaCha20-based ciphers have been added. This includes the ChaCha20 stream cipher itself, as well as the ChaCha20-Poly1305 construction.
8 rounds ChaCha20 provides a 2.5x speedup over the standard 20 rounds version, and is still believed to have a safe security margin.
Breaking Changes §
- Edwards25519:
neutralElementwas deprecated. New code should useidentityElementinstead. - Errors have been made more consistent across
std.cryptofunctions. They now all share the samestd.crypto.Errorerrors set.
Performance Improvements §
- Ed25519 signature verification is about 60% faster than in Zig 0.7.1.
Crypto Bug Fixes §
- AES:
{encrypt,decrypt}Wide()functions performed more rounds than necessary. This has been fixed. - BLAKE2: properly handle output sizes that are not a multiple of 8.
- Salsa20: the vectorized implementation didn't use the correct position for the internal counter.
Contributors: Frank Denis, Andrew Kelley, LemonBoy, Al Hoang, Guillaume Ballet, Isaac Freund, Jay Petacat, Matt Sicker, Rocknest, Tadeo Kondrak, Veikka Tuominen
MultiArrayList §
One pattern commonly observed in Data-Oriented Design is Struct of Arrays (SOA). This can be useful when reworking memory layout to be more CPU-cache-friendly.
Some programming languages have experimented with support for SoA at the language level. In Zig, this abstraction is now provided in the standard library; no language modifications needed.
The purpose of this data structure is to provide a similar API to
ArrayList but instead of the element type being a struct,
the fields of the struct are in N different arrays, all with the same length and capacity.
Having this abstraction means we can put them in the same allocation, avoiding overhead with the allocator. It also saves a tiny bit of overhead from the redundant capacity and length fields, since each struct element shares the same value.
Here is an example of using this data structure:
multi_array_list.zig
const std = @import("std");
const Allocator = std.mem.Allocator;
const MultiArrayList = std.MultiArrayList;
const ArrayList = std.ArrayListUnmanaged;
const MyData = struct {
tag: enum { one, two },
pointer: *i32,
};
pub fn main() !void {
{
var gpa: std.heap.GeneralPurposeAllocator(.{
.enable_memory_limit = true,
}) = .{};
defer _ = gpa.deinit();
var list: ArrayList(MyData) = .{};
defer list.deinit(&gpa.allocator);
try addSomeItems(&gpa.allocator, &list);
std.debug.print("ArrayList: {}\n", .{
std.fmt.fmtIntSizeBin(gpa.total_requested_bytes),
});
}
{
var gpa: std.heap.GeneralPurposeAllocator(.{
.enable_memory_limit = true,
}) = .{};
defer _ = gpa.deinit();
var list: MultiArrayList(MyData) = .{};
defer list.deinit(&gpa.allocator);
try addSomeItems(&gpa.allocator, &list);
std.debug.print("MultiArrayList: {}\n", .{
std.fmt.fmtIntSizeBin(gpa.total_requested_bytes),
});
}
}
var derp: i32 = 0;
fn addSomeItems(gpa: *Allocator, list: anytype) !void {
var i: usize = 0;
while (i < 10000) : (i += 1) {
try list.append(gpa, .{
.pointer = &derp,
.tag = if (i % 1 == 0) .one else .two,
});
}
}$ zig build-exe multi_array_list.zig
$ ./multi_array_list
ArrayList: 160KiB
MultiArrayList: 91.177734375KiB
Here is illustrated the same struct added ten thousand times to an ArrayList, and also to a MultiArrayList, and observe that the MultiArrayList uses only 57% of the memory as the ArrayList, due to not wasting the padding bytes between the 1-byte enum field and the pointer field.
On modern hardware, this can make a big difference due to lower L1 cache pressure on the CPU.
This abstraction was immediately useful, unlocking both Reworked Memory Layout in the Self-Hosted Compiler as well as hash map improvements in this release cycle.
Hash Maps §
Martin Wickham made
sweeping changes
to HashMap and ArrayHashMap APIs as part of 0.8.0, resolving
the following issues:
- Hash Context Types (#8528).
- Adapting Contexts (#8619).
- New
getPtr()function returns a pointer to value (#7489). - Separated Key/Value Storage (#8363).
- BufSet/BufMap functions renamed to match other set/map types (#8971).
Preexisting code that uses these APIs will need to update.
Additionally, the following miscellaneous improvements were made:
- Fixed HashMap.putAssumeCapacity and HashMap.clearRetainingCapacity (#7061).
- Fixed AutoArrayHashMap's store_hash logic.
- ArrayHashMap: ensureUnusedCapacity and ensureTotalCapacity.
- Removed empty init from HashMapUnmanaged.
- ArrayHashMap: decrement entries slice len after popping from entries in pop() to prevent OOB.
- ArrayHashMap: add "AssertDiscard" function variants.
- Support equivalent ArrayList operations in ArrayHashMap.
Hash Context Types §
Hash map types which accept a hash and eql function have been refactored to instead
require a Context type. Context types must have member functions hash
and eql which will perform the hash. Example context for strings:
pub const StringContext = struct {
pub fn hash(self: @This(), s: []const u8) u64 {
return hashString(s);
}
pub fn eql(self: @This(), a: []const u8, b: []const u8) bool {
return eqlString(a, b);
}
};Note that, like before, ArrayHashMap requires 32-bit hashes and HashMap requires 64-bit hashes.
Context types may also have fields.
pub const StringPoolContext = struct {
pool: StringPool,
pub fn hash(self: @This(), s: StringPool.ID) u64 {
return self.pool.getStringHash(s);
}
pub fn eql(self: @This(), a: StringPool.ID, b: StringPool.ID) bool {
return a == b;
}
};When using a nonempty context with a Managed hash map type, the context instance
is stored within the managed instance. The instance must be created with
initContext instead of the usual init function.
For Unmanaged hash map types, you must now call Context variants of the hash map functions to pass in a context instance:
map.put(k, v)=>map.putContext(k, v, ctx)map.get(k)=>map.getContext(k, ctx)map.remove(k)=>map.removeContext(k, ctx)- etc.
However, the old functions still exist, and will work as long as the context is zero sized.
Adapting Contexts §
In addition to Contexts, you can now create Adapting Contexts, which allow you to use specialized keys with the map. For example:
pub const StringPoolAdaptingContext = struct {
pool: StringPool,
pub fn hash(self: @This(), k: []const u8) u64 {
return hashString(k);
}
pub fn eql(self: @This(), new_key: []const u8, stored_key: StringPool.ID) bool {
return eqlString(new_key, self.pool.getString(stored_key));
}
};This adapting context can be used to query a map which uses the
StringPoolContext from the previous section. The adapter allows queries
to be performed using keys which may or may not actually be in the string pool.
To enable this, it provides hashing for the adapted key, and a comparison function
between the adapted key and a stored key.
New functions with names ending in Adapted allow these adapting contexts
to be passed in.
Separated Key/Value Storage §
Before 0.8.0, keys and values were stored in an array of structs of
Entry{K, V}. This storage wastes a lot of memory if keys and values
have differing alignment, and for ArrayHashMap incurs performance
penalties when iterating over only keys or only values.
With this change, hash maps now store two separated arrays of
keys and values.
This means that existing APIs which return *Entry can no longer be supported.
The following breaking changes have been made:
Entryhas been changed fromstruct { key: K, value: V }tostruct { key_ptr: *K, value_ptr: *V }.- A new struct
KVisstruct { key: K, value: V }. - APIs which used to return
*Entrynow returnEntry. - APIs which used to return
Entrynow returnKV.
Here are some examples for updating code to use the new API:
Example 1:
// old
var it = hash_map.iterator();
while (it.next()) |entry| {
const k = entry.key;
const v = entry.value;
}
// new
var it = hash_map.iterator();
while (it.next()) |entry| {
const k = entry.key_ptr.*;
const v = entry.value_ptr.*;
}Example 2:
// old
for (array_hash_map.entries.items) |entry| {
free(entry.key);
free(entry.value);
}
// new
for (array_hash_map.keys()) |key| {
free(key);
}
for (array_hash_map.values()) |value| {
free(value);
}Example 3:
// old
for (array_hash_map.entries.items) |entry| {
useBoth(entry.key, entry.value);
}
// new
var it = array_hash_map.iterator()
while (it.next()) |entry| {
useBoth(entry.key_ptr.*, entry.value_ptr.*);
}
// After accepted proposal https://github.com/ziglang/zig/issues/7257 is implemented:
for (array_hash_map.keys(), array_hash_map.values()) |key, value| {
useBoth(key, value);
}Example 4:
// old
const result = try map.getOrPut(key);
if (!result.found_existing) {
result.entry.value = new_value;
}
// new
const result = try map.getOrPut(key);
if (!result.found_existing) {
result.value_ptr.* = new_value;
}Renamed Functions §
In addition to the above changes, several functions have been renamed to better
reflect their operation and to improve consistency. These changes also affect the
BufMap and BufSet APIs.
ensureCapacityhas been split intoensureTotalCapacityandensureAdditionalCapacityHashMap.removenow returnsbool, a new functionfetchRemovereturns?KVremoveAssertDiscardhas been deleted, useassert(map.remove(key))instead.ArrayHashMap.removehas been split into six variants (not including adapted/context variants)orderedRemove(K) boolorderedRemoveAt(usize) boolfetchOrderedRemove(K) ?KVswapRemove(K) boolswapRemoveAt(usize) boolfetchSwapRemove(K) ?KV
BufSet.putis nowBufSet.insertBufSet.existsis nowBufSet.containsBufSet.deleteis nowBufSet.removeBufSet.iteratornow iterates over key values onlyBufMap.setis nowBufMap.putBufMap.setMoveis nowBufMap.putMoveBufMap.deleteis nowBufMap.remove
Progress §
This is the API that provides a progress bar for terminal applications. You've probably seen it since the Zig compiler itself uses it.
There is now better handling of line-wrapping:
In order to update the printed progress string the code tried to move the cursor N cells to the left, where N is the number of written bytes, and then clear the remaining part of the line. This strategy has two main issues:
- Is only valid if the number of characters is equal to the number of written bytes.
- Is only valid if the line doesn't get too long.
The second point is the main motivation for this change, when the line becomes too long the terminal wraps it to a new physical line. This means that moving the cursor to the left won't be enough anymore as once the left border is reached it cannot move anymore.
The wrapped line is still stored by the terminal as a single line, despite now taking more than a single one when displayed. If you try to resize the terminal you'll notice how the contents are reflowed and are essentially illegible.
Querying the cursor position on non-Windows systems (plot twist, Microsoft suggests using VT escape sequences on newer systems) is extremely cumbersome so the new implementation does something different.
Before printing anything it saves the cursor position and clears the screen below the cursor, this way we ensure there's absolutely no trace of stale data on screen, and after the message is printed we simply restore it.
There are still some major flaws with the way the code is implemented to interact with terminals, and contributions are welcome to improve it.
Testing §
std.testing now uses errors to fail tests. Callsites
will have to adjust to use try:
Old:
test.zig
const std = @import("std");
const testing = std.testing;
test "old" {
std.testing.expect(true);
}$ zig test test.zig
./docgen_tmp/test.zig:5:23: error: error is ignored. consider using `try`, `catch`, or `if`
std.testing.expect(true);
^
./docgen_tmp/test.zig:4:12: note: referenced here
test "old" {
^
New:
test.zig
const std = @import("std");
const testing = std.testing;
test "new" {
try std.testing.expect(true);
}$ zig test test.zig
Test [1/1] test "new"...
All 1 tests passed.
The default test runner is modified so that when a test returns an error, the test is marked as failure, however subsequent tests are still run. At the end is reported the failures and successes, and the final exit code of zig test will be 0 if and only if all tests succeeded with no memory leaks.
A --fail-fast flag is planned to be added to zig test to get the
old behavior back, but it is not yet implemented.
Orphanage §
The Zig Standard Library Orphanage has started adopting.
This is code that used to be in the standard library, but there wasn't any reason to keep maintaining it there when it could function just fine as a third party package.
Feel free to start your own source code repository and take over the duties of maintaining any of this code. You can send PRs to the README to link to your project.
The following APIs are up for adoption:
- SegmentedList (#7190)
- Serialization
- ArrayListSentineled
- BloomFilter
- HttpHeaders
- RedBlackTree
Zig Build System §
The Zig Build System is invoked via the zig build command, which executes
a declarative build.zig script to collect options and describe the graph
of steps, and then provides options to execute those steps.
Although it is already essential to nearly every Zig project, the Zig Build System is still experimental and unstable. As a build system, stability is especially important, but stabilization cannot occur until the language stabilizes. Language stability is the next area of focus on the Roadmap.
The first thing you will immediately notice in this release is that the
default install prefix is now zig-out in the build root, rather than
zig-cache in the current working directory (#8659). The -p
flag can be used to choose a different install prefix.
In addition, there are the following improvements:
- Support specifying rpaths explicitly (#8912).
installDirectorysupports ablank_extensionsoption to blank out files instead of omitting them. This is utilized by Zig's build script so that the installation does not include many megabytes of test files, but also@importon them does not cause a compile error.- Added experimental Darling support for cross testing macOS.
- Fixed wrong glibc dir passed to qemu for i386.
- If using a RunStep, show the command run on verbose (#8571).
- Added LibExeObjStep.linker_allow_shlib_undefined field to set --allow-shlib-undefined
- std.build: make Builder.install_prefix non optional This is useful for build.zig files to check in some cases, for example to adhere to the convention of installing config to /etc instead of /usr/etc on linux when using the /usr prefix. Perhaps std.build will handle such common cases eventually, but that is not yet the case.
- Added support for LTO configuration.
- Added support for passing write file args as build options (#7909). Makes it easier to generate Zig code in a build.zig script.
- Dupe strings on all public api points for std.build.
- Propagate env_map for child processes.
- Assert that install paths are relative. If absolute paths are passed they will work unless $DESTDIR is set, which causes subtly broken build.zig's.
- Made build errors followed by two newlines.
- Added
sanitize_threadoption. - Added option to override default stack size in build system.
addBuildOptiongains support for more types:SemanticVersion, floats,?[:0]const u8- Dynamic library artifacts are now passed as positionals.
- COFF linking: fix incorrectly passing .dll instead of .lib
Contributors: Andrew Kelley, Asherah Connor, Daniele Cocca, Frank Denis, Hubert Jasudowicz, Isaac Freund, Jakub Konka, Jay Petacat, Jonathan Marler, Josh Holland, Lee Cannon, LemonBoy, Martin Wickham, Michael Dusan, Michael Holmes, Ryan Greenblatt, Veikka Tuominen, Vexu, Vincent Rischmann, antlilja, daurnimator, frmdstryr, Jacob G-W, lithdew, rgreenblatt
Toolchain §
Thread Sanitizer §
The -fsanitize-thread option is now available to detect data races.
This is based on
Clang's ThreadSanitizer.
musl 1.2.2 §
Zig ships with the source code to musl. When the musl C ABI is selected, Zig builds musl from source for the selected target.
This release updates the bundled musl source code to v1.2.2.
Additionally, Isaac Freund contributed the ability to target dynamically linked musl (#7406). This greatly improves the behavior of Zig on Linux distributions that use musl as their libc, such as Alpine Linux.
glibc 2.33 §
Zig gains the ability to target glibc 2.33 in addition to the other 43 glibc versions.
mingw-w64 9.0.0 §
Zig ships with the source code to mingw-w64. When targeting *-windows-gnu and linking against libc, Zig builds mingw-w64 from source for the selected target.
This release updates the bundled mingw-w64 source code to v9.0.0.
WASI libc §
Zig now ships with WASI libc and supports cross-compiling C code to WASI. See also WebAssembly Support.
zig ar §
New subcommand: zig ar which is a drop-in replacement for ar.
zig cc §
Zig now automatically uses a thread pool to compile C objects in parallel. For users with multiple CPU cores this will make a huge difference in how long it takes to compile C and C++ objects.
zig cc is covered by the Bug Stability Program. This means that, even
prior to Zig 1.0, we will not tag a release with any known regressions in zig cc.
Some caveats: this applies to only the Zig codebase; we cannot promise that
Clang will not regress.
Also please be aware that there are open zig cc issues, but these are things that never worked in the first place, making them bugs and enhancements, not regressions.
Apart from parallelization, mainly the improvements in this release are polish and bug fixes, bringing us materially closer to the "it just works" user experience:
- Made
zig ccprint more info from Clang itself and from our own linker invocation. This is needed for CMake to properly discover all the include directories and library search paths (#7110, #7166). - Made SONAME off by default when using
zig ccto match C compilers.zig build-lib -dynamicstill defaults SONAME to on. - Default to a.exe on Windows, matching Clang.
- Support both ubsan and tsan at the same time.
- Support reading input from stdin, fixing use of
zig ccwith meson (#6271. - Recognize more coff linker options (#7874).
- Recognize the
-sflag to be "strip". - Fixed handling of
-MMflag, as well as-MG,-MM, and-MMDaliases. - Copy .pdb files from zig-cache/ when appropriate (#8407).
- Properly pass -mcpu option when assembling.
- Expose header files when linking libunwind.
- Implicitly enable
--eh_frame_hdrwhen compiling C/C++ files. Matches what Clang/GCC driver do (#7711).
Environment Variable Alternatives to CLI Options §
This release adds:
ZIG_LOCAL_CACHE_DIRcorresponding to--cache-dirZIG_GLOBAL_CACHE_DIRcorresponding to--global-cache-dirZIG_LIB_DIRcorresponding to--override-lib-dirZIG_VERBOSE_LINKcorresponding to--verbose-linkZIG_VERBOSE_CCcorresponding to--verbose-cc
Generally the CLI options that Zig provides are preferable to using environment variables,
however, when using zig cc, we are bound by Clang's CLI options and
therefore need alternate channels to pass these configuration options.
Improved Local Cache Directory Logic §
Previously, when choosing the local cache directory, if there was no root source file, an explicitly chosen path, or other clues, zig would choose cwd + zig-cache/ as the local cache directory.
This can be problematic if Zig is invoked with the CWD set to a
read-only directory, or a directory unrelated to the actual source files
being compiled. In the real world, we see this when using zig cc with
CGo, which for some reason changes the current working directory to the
read-only go standard library path before running the C compiler.
This change conservatively chooses to use the global cache directory as the local cache directory when there is no other reasonable choice, and no longer will rely on the cwd path to choose a local cache directory.
As a reminder, the --cache-dir CLI flag and ZIG_LOCAL_CACHE_DIR
environment variable are available for overriding the decision. For the
zig build system, it will always choose the directory that build.zig is + zig-cache/.
With this, plus a commit that landed in Go 1.17, Zig Makes Go Cross Compilation Just Work.
Another user saw this and noticed that additionally, Zig Makes Rust Cross-compilation Just Work.
Contributors: Andrew Kelley, Jakub Konka, LemonBoy, Rafael Ristovski, Jacob G-W
zig c++ §
zig c++ is equivalent to zig cc with an added -lc++
parameter, but I made a separate heading here because I realized that some people are
not aware that Zig supports compiling C++ code and providing libc++ too!
#include <iostream>
int main() {
std::cout << "Hello World!" << std::endl;
return 0;
}$ zig c++ -o hello hello.cpp $ ./hello Hello World!
Cross-compiling too, of course:
$ zig c++ -o hello hello.cpp -target riscv64-linux $ qemu-riscv64 ./hello Hello World!
One thing that trips people up when they use this feature is that the C++ ABI is not stable across compilers, so always remember the rule: You must use the same C++ compiler to compile all your objects and static libraries. This is an unfortunate limitation of C++ which Zig can never fix.
Bug Fixes §
Full list of the 106 bug reports closed during this release cycle.
Note: many bugs were both introduced and resolved within this release cycle.
This Release Contains Bugs §
Zig has known bugs and even some miscompilations.
Zig is immature. Even with Zig 0.8.0, working on a non-trivial project using Zig will likely require participating in the development process.
When Zig reaches 1.0.0, a new requirement for Tier 1 Support will be 0 known bugs for that target.
A 0.8.1 release is planned.
News §
Frank Denis joins the Core Zig Team §
Frank has completely organized, modernized, fixed, and fleshed out Standard Library Crypto, as well as other parts of the standard library. He also delivered a Zig Showtime talk on 25519.
Frank has shown continued dedication and discipline in contributions to the Zig programming language project. The quality of his work speaks for itself.
In addition, Frank has proven to be a steadfast community leader, setting an example for how to treat others with kindness and respect.
kprotty joins the Core Zig Team §
I am pleased to announce our newest Zig team member, kprotty. If you've interacted with him, you know that he has an insatiable appetite for concurrency-related performance, based on a deep understanding that only comes from dedication and experimentation.
Check out his related Showtime talks:
kprotty's contributions to the Zig standard library are core to the success of the project.
In addition, kprotty has proven to be a steadfast community leader, setting an example for how to treat others with kindness and respect.
LemonBoy Gains LLVM Write Access §
If you read even a little bit of these release notes, you probably noticed that LemonBoy did an incredible amount of work for Zig.
But this mad man did not only that, but also submitted patches to LLVM upstream to fix Zig-related issues that came up. So much so, recently, that he was granted write access to the LLVM repository.
Congrats to LemonBoy and thank you for your contributions.
Loris Cro Gets a Raise §
Loris was the first person hired by the Zig Software Foundation. At the time, Andrew's plan was to pay him out of his personal savings account. However, within just two weeks of work, Loris already paid for himself and more, by helping to get more donations.
Until now his hourly rate has been 40 USD/hour, but now it is 50 USD/hour, same as the other contractors. So, Loris: please start billing ZSF at this higher rate!
License Tweak §
In celebration of this 0.8.0 release, Andrew made a small tweak to the LICENSE file of the main Zig repository:
--- a/LICENSE
+++ b/LICENSE
@@ -1,6 +1,6 @@
The MIT License (Expat)
-Copyright (c) 2015 Andrew Kelley
+Copyright (c) 2015-2021, Zig contributors
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to dealThank you everyone for your amazing contributions over the past years! ❤️
Roadmap §
The major theme of the 0.9.0 release cycle will be stabilizing the language, creating a first draft of the language specification, and self-hosting the compiler.
I am now confident that we can ship the Self-Hosted Compiler with the 0.9.0 release of Zig.
Package Manager Status §
Having a package manager built into the Zig compiler is a long-anticipated feature. Zig 0.8.0 does not have this feature.
If the package manager works well, people will use it, which means building Zig projects will involve compiling more lines of Zig code, which means the Zig compiler must get faster, better at incremental compilation, and better at resource management.
Therefore, the package manager depends on finishing the Self-Hosted Compiler, since it is planned to have these improved performance characteristics, while the Bootstrap Compiler is not planned to have them.
Accepted Proposals §
If you want more of a sense of the direction Zig is heading, you can look at the set of accepted proposals.
Thank You LavaTech §
Special thanks to Ave and Luna of LavaTech, who are hosting an instance of SourceHut for our Continuous Integration pipeline, but with more RAM than the main sr.ht service allows. Thanks to this, FreeBSD now has significantly more test coverage, most notably all the standard library tests.
Thank You Sponsors! §
Special thanks to those who sponsor Zig. Because of you, Zig is driven by the open source community, rather than the goal of making profit. In particular, these fine folks sponsor Zig for $50/month or more:
- Pex
- drfuchs
- Lager Data
- Stevie Hryciw
- Karrick McDermott
- Joran Dirk Greef
- Simon A. Nielsen Knights
- Stephen Gutekanst
- ConnectEverything
- Derek Collison
- Dustin Taylor
- Josh Wolfe
- Matthew Knight
- ryanworl
- Jethro Nederhof
- Björn Linse
- wilsonk
- David Vanderson
- SkunkWerks GmbH
- tawawhite
- Ryan Saunderson
- Isaac Yonemoto
- Felix Queißner
- devzero
- Luuk de Gram
- Jamie Brandon
- Auguste Rame
- Jay Petacat
- Michal Ziulek
- Vincent Rischmann
- seadragon-droid
- Asherah Connor
- meraymond2
- Dirk de Visser
- Santiago Andaluz
- Martin Wickham
- José M Rico
- Steve Powers
- Yaroslav Zhavoronkov
- Agam Dua
- Rui Ueyama
- mbarkhau
- Clay Kuppinger
- Charlie Cheever
- Anton Kochkov
- Martin Schwaighofer
- Jesus Alvarez
- Max Bernstein
- Rand Fitzpatrick
- Timothy Ham
- Robert Hencke
- Max De Marzi
- Christopher Kennedy
- Jordan Orelli
- Keith Devens
- jamesmcgill
- Luke Champine
- Neil Wang
- Mitchell Kember
- Christopher David Shirk
- Mamadou S Diallo
- Matyas Tamas
- Daniel Hensley
- cryptocode
- Andrew Gallant
- Erik Lundin
- Christopher Dolan
- Tom Maenan Read Cutting
- Robert Krahn