0.15.1 Release Notes

Zig is a general-purpose programming language and toolchain for maintaining robust, optimal, and reusable software.
Zig development is funded via Zig Software Foundation, a 501(c)(3) non-profit organization. Please consider a recurring donation so that we can offer more billable hours to our core team members. This is the most straightforward way to accelerate the project along the Roadmap to 1.0.
If you need receipts for your donations or are looking to migrate away from GitHub Sponsors, we recommend donating to us via Every.org.
This release features 5 months of work: changes from 162 different contributors, spread among 647 commits.
Debug compilation is 5 times faster with Zig's x86 Backend selected by default; the work-in-progress aarch64 Backend hot on its heels. Meanwhile, the Writergate scandal, along with a slew of Language Changes and Standard Library cuts, rocks the boat with tidal waves of breaking API changes; the harbinger of async/await resurrection; the last bastion defending language stabilization.
Table of Contents §
- Table of Contents
- Target Support
- Language Changes
- Standard Library
- Writergate
- "{f}" Required to Call format Methods
- Format Methods No Longer Have Format Strings or Options
- Formatted Printing No Longer Deals with Unicode
- New Formatted Printing Specifiers
- De-Genericify Linked Lists
- std.Progress supports progress bar escape codes
- HTTP Client and Server
- TLS Client
- ArrayList: make unmanaged the default
- Ring Buffers
- Removal of BoundedArray
- Deletions and Deprecations
- Build System
- Compiler
- Linker
- Fuzzer
- Bug Fixes
- Toolchain
- Roadmap
- Thank You Contributors!
- Thank You Sponsors!
Target Support §
Zig supports a wide range of architectures and operating systems. The Support Table and Additional Platforms sections cover the targets that Zig can build programs for, while the zig-bootstrap README covers the targets that the Zig compiler itself can be easily cross-compiled to run on.
Tier System §
Zig's level of support for various targets is broadly categorized into four tiers with Tier 1 being the highest. The goal is for Tier 1 targets to have zero disabled tests - this will become a requirement for post-1.0.0 Zig releases.
Tier 1 §
- All non-experimental language features are known to work correctly.
- The compiler can generate machine code for this target without relying on LLVM, while being comparable to LLVM in terms of feature support.
- The CI machines automatically run the module tests for this target on every push.
Tier 2 §
- The standard library's cross-platform abstractions have implementations for this target.
- This target has debug info capabilities and therefore produces stack traces on failed assertions and crashes.
- libc is available for this target even when cross-compiling.
- The CI machines automatically build the module tests for this target on every push.
Tier 3 §
- The compiler can generate machine code for this target by relying on an external backend such as LLVM.
- The linker can produce object files, libraries, and executables for this target.
Tier 4 §
- The compiler can generate assembly source code for this target by relying on an external backend such as LLVM.
- This target may be considered experimental by LLVM, in which case it is necessary to build LLVM and Zig from source to be able to use it.
Support Table §
In the following table, 🟢 indicates full support, 🔴 indicates no support, and 🟡 indicates that there is partial support, e.g. only for some sub-targets, or with some notable known issues. ❔ indicates that the status is largely unknown, typically because the target is rarely exercised. Hover over other icons for details.
| Target | Tier | Lang. Feat. | Std. Lib. | Code Gen. | Linker | Debug Info | libc | CI |
|---|---|---|---|---|---|---|---|---|
x86_64-linux |
1 | 🟢 | 🟢 | 🖥️⚡ | 🟢 | 🟢 | 🟢 | 🟢 |
x86_64-macos |
1 | 🟢 | 🟢 | 🖥️⚡ | 🟢 | 🟢 | 🟢 | 🟢 |
|
|
||||||||
aarch64-freebsd |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟡 |
aarch64(_be)-linux |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟢 |
aarch64(_be)-netbsd |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟡 |
aarch64-macos |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟢 |
aarch64-windows |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟡 |
arm-freebsd |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟡 |
arm(eb)-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟢 |
arm(eb)-netbsd |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟡 |
loongarch64-linux |
2 | 🟡 | 🟡 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟡 |
powerpc-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟡 | 🟢 | 🟢 | 🟢 |
powerpc-netbsd |
2 | 🟢 | 🟢 | 🖥️ | 🟡 | 🟢 | 🟢 | 🟡 |
powerpc64-freebsd |
2 | 🟢 | 🟢 | 🖥️ | 🟡 | 🟢 | 🟢 | 🟡 |
powerpc64-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟡 | 🟢 | 🟢 | 🟢 |
powerpc64le-freebsd |
2 | 🟢 | 🟢 | 🖥️ | 🟡 | 🟢 | 🟢 | 🟡 |
powerpc64le-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟡 | 🟢 | 🟢 | 🟢 |
riscv32-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟡 | 🟢 | 🟢 |
riscv64-freebsd |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟡 | 🟢 | 🟡 |
riscv64-linux |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟡 | 🟢 | 🟢 |
thumb-windows |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟡 |
thumb(eb)-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟢 |
wasm32-wasi |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟡 | 🟢 | 🟢 |
x86-linux |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟢 |
x86-windows |
2 | 🟢 | 🟢 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟡 |
x86_64-freebsd |
2 | 🟢 | 🟢 | 🖥️⚡ | 🟢 | 🟢 | 🟢 | 🟡 |
x86_64-netbsd |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟡 |
x86_64-windows |
2 | 🟢 | 🟢 | 🖥️🛠️ | 🟢 | 🟢 | 🟢 | 🟢 |
|
|
||||||||
aarch64-haiku |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟢 | 🔴 | 🔴 |
aarch64-openbsd |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟢 | 🔴 | 🔴 |
aarch64-serenity |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟢 | 🔴 | 🔴 |
arm-haiku |
3 | 🟢 | 🟡 | 🖥️ | 🟢 | 🟢 | 🔴 | 🔴 |
arm-openbsd |
3 | 🟢 | 🟡 | 🖥️ | 🟢 | 🟢 | 🔴 | 🔴 |
hexagon-linux |
3 | 🟡 | 🟡 | 🖥️ | 🟢 | 🟢 | 🟢 | 🟡 |
mips(el)-linux |
3 | 🟢 | 🟢 | 🖥️ | 🟢 | 🔴 | 🟢 | 🟢 |
mips(el)-netbsd |
3 | 🟢 | 🟢 | 🖥️ | 🟢 | 🔴 | 🟢 | 🟡 |
mips64(el)-linux |
3 | 🟢 | 🟢 | 🖥️ | 🟢 | 🔴 | 🟢 | 🟢 |
mips64(el)-netbsd |
3 | 🟢 | 🟢 | 🖥️ | 🟢 | 🔴 | 🟢 | 🟡 |
mips64(el)-openbsd |
3 | 🟢 | 🟡 | 🖥️ | 🟢 | 🔴 | 🔴 | 🔴 |
powerpc-openbsd |
3 | 🟢 | 🟡 | 🖥️ | 🟢 | 🟢 | 🔴 | 🔴 |
powerpc64-openbsd |
3 | 🟢 | 🟡 | 🖥️ | 🟢 | 🟢 | 🔴 | 🔴 |
riscv64-haiku |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟡 | 🔴 | 🔴 |
riscv64-openbsd |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟡 | 🔴 | 🔴 |
riscv64-serenity |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟡 | 🔴 | 🔴 |
s390x-linux |
3 | 🟢 | 🟢 | 🖥️ | 🟢 | 🔴 | 🟢 | 🟢 |
sparc64-linux |
3 | ❔ | 🟢 | 🖥️🛠️ | 🟡 | ❔ | 🟢 | 🔴 |
sparc64-netbsd |
3 | ❔ | 🟢 | 🖥️🛠️ | 🟡 | ❔ | 🟢 | 🔴 |
sparc64-openbsd |
3 | ❔ | 🟡 | 🖥️🛠️ | 🟡 | ❔ | 🔴 | 🔴 |
sparc64-solaris |
3 | ❔ | 🟡 | 🖥️🛠️ | 🟡 | ❔ | 🔴 | 🔴 |
wasm64-wasi |
3 | ❔ | 🔴 | 🖥️🛠️ | 🟢 | 🟡 | 🔴 | 🔴 |
x86_64-dragonfly |
3 | 🟢 | 🟡 | 🖥️⚡ | 🟢 | 🟢 | 🔴 | 🔴 |
x86_64-haiku |
3 | 🟢 | 🟡 | 🖥️⚡ | 🟢 | 🟢 | 🔴 | 🔴 |
x86_64-illumos |
3 | 🟢 | 🟡 | 🖥️⚡ | 🟢 | 🟢 | 🔴 | 🔴 |
x86_64-openbsd |
3 | 🟢 | 🟡 | 🖥️🛠️ | 🟢 | 🟢 | 🔴 | 🔴 |
x86_64-serenity |
3 | 🟢 | 🟡 | 🖥️⚡ | 🟢 | 🟢 | 🔴 | 🔴 |
x86_64-solaris |
3 | 🟢 | 🟡 | 🖥️⚡ | 🟢 | 🟢 | 🔴 | 🔴 |
|
|
||||||||
arc-linux |
4 | ❔ | 🟡 | 📄 | 🔴 | ❔ | 🟢 | 🔴 |
csky-linux |
4 | ❔ | 🟡 | 📄 | 🔴 | ❔ | 🟢 | 🔴 |
m68k-linux |
4 | ❔ | 🟡 | 🖥️ | 🔴 | ❔ | 🟢 | 🔴 |
m68k-netbsd |
4 | ❔ | 🟡 | 🖥️ | 🔴 | ❔ | 🟢 | 🔴 |
sparc-linux |
4 | ❔ | 🟡 | 🖥️ | 🔴 | ❔ | 🟢 | 🔴 |
xtensa-linux |
4 | ❔ | 🔴 | 📄 | 🔴 | ❔ | 🔴 | 🔴 |
OS Version Requirements §
The Zig standard library has minimum version requirements for some supported operating systems, which in turn affect the Zig compiler itself.
| Operating System | Minimum Version |
|---|---|
| Dragonfly BSD | 6.0 |
| FreeBSD | 14.0 |
| Linux | 5.10 |
| NetBSD | 10.1 |
| OpenBSD | 7.6 |
| macOS | 13.0 |
| Solaris | 11 |
| Windows | 10 |
Additional Platforms §
Zig also has varying levels of support for these targets, for which the tier system does not quite apply:
aarch64-driverkitaarch64(_be)-freestandingaarch64-iosaarch64-tvosaarch64-uefiaarch64-visionosaarch64-watchosamdgcn-amdhsaamdgcn-amdpalamdgcn-mesa3darc-freestandingarm(eb)-freestandingarm-uefiavr-freestandingbpf(eb,el)-freestandingcsky-freestandinghexagon-freestandingkalimba-freestandinglanai-freestandingloongarch(32,64)-freestandingloongarch(32,64)-uefim68k-freestandingmips(64)(el)-freestandingmsp430-freestandingnvptx(64)-cudanvptx(64)-nvclpowerpc(64)(le)-freestandingpropeller-freestandingriscv(32,64)-freestandingriscv(32,64)-uefis390x-freestandingsparc(64)-freestandingspirv(32,64)-openclspirv(32,64)-openglspirv(32,64)-vulkanthumb(eb)-freestandingve-freestandingwasm(32,64)-emscriptenwasm(32,64)-freestandingx86(_64)-freestandingx86(_64)-uefix86_64-driverkitx86_64-iosx86_64-tvosx86_64-visionosx86_64-watchosxcore-freestandingxtensa-freestanding
Language Changes §
Minor changes:
- packed union fields are no longer allowed to specify an align attribute, matching the existing behaviour with packed structs. Providing an override for the alignment previously did not affect the alignment of fields, and migration to these new rules takes the form of deleting the specifier. #22997
usingnamespace Removed §
This keyword added distance between the "expected" definition of a declaration
and its "actual" definition. Without it, discovering a declaration's definition
site is incredibly simple: find the definition of the namespace you are
looking in, then find the identifier being defined within that type
declaration. With usingnamespace, however, the
programmer can be led on a wild goose chase through different types and
files.

Not only does this harm readability for humans, but it is also
problematic for tooling; for instance, Autodoc cannot reasonably see
through non-trivial uses of usingnamespace (try looking for dl_iterate_phdr
under std.c in the 0.14.1 documentation).
By eliminating this feature, all identifiers can be trivially traced back to where they are imported - by humans and machines alike.
Additionally, usingnamespace encourages poor namespacing.
When declarations are stored in a separate file, that typically means they
share something in common which is not shared with the contents of another
file. As such, it is likely a very reasonable choice to actually expose the
contents of that file via a separate namespace, rather than including them
in a more general parent namespace. To put it shortly: namespacing
is good, actually.
Finally, removal of this feature makes Incremental Compilation fundamentally simpler.
Use Case: Conditional Inclusion §
usingnamespace can be used to conditionally include a declaration as follows:
pub usingnamespace if (have_foo) struct {
pub const foo = 123;
} else struct {};The solution here is pretty simple: usually, you can just include the declaration unconditionally. Zig's lazy compilation means that it will not be analyzed unless referenced, so there are no problems!
pub const foo = 123;Occasionally, this is not a good solution, as it lacks safety. Perhaps
analyzing foo will always work, but will only give a meaningful
result if have_foo is true, and it would be a bug to use it in any
other case. In such cases, the declaration can be conditionally made a compile
error:
pub const foo = if (have_foo)
123
else
@compileError("foo not supported on this target");This does break feature detection with @hasDecl. If feature detection is needed, a better approach—less prone to typos and bitrotting—is to conditionally initialize the declaration to some "sentinel" value which can be detected. A good choice is often the void value {}:
const something = struct {
// In this example, `foo` is supported but `bar` is not.
const have_foo = true;
const have_bar = false;
pub const foo = if (have_foo) 123 else {};
pub const bar = if (have_bar) undefined else {};
};
test "use foo if supported" {
if (@TypeOf(something.foo) == void) return error.SkipZigTest; // unsupported
try expect(something.foo == 123);
}
test "use bar if supported" {
if (@TypeOf(something.bar) == void) return error.SkipZigTest; // unsupported
try expect(something.bar == 456);
}
const expect = @import("std").testing.expect;$ zig test feature-detection.zig 1/2 feature-detection.test.use foo if supported...OK 2/2 feature-detection.test.use bar if supported...SKIP 1 passed; 1 skipped; 0 failed.
Use Case: Implementation Switching §
A close cousin of conditional inclusion, usingnamespace can also be used to select from multiple implementations of a declaration at comptime:
pub usingnamespace switch (target) {
.windows => struct {
pub const target_name = "windows";
pub fn init() T {
// ...
}
},
else => struct {
pub const target_name = "something good";
pub fn init() T {
// ...
}
},
};The alternative to this is simpler and results in better code: make the definition itself a conditional.
pub const target_name = switch (target) {
.windows => "windows",
else => "something good",
};
pub const init = switch (target) {
.windows => initWindows,
else => initOther,
};
fn initWindows() T {
// ...
}
fn initOther() T {
// ...
}Use Case: Mixins §
A very common use case for usingnamespace in the wild was to implement mixins:
/// Mixin to provide methods to manipulate the `count` field.
pub fn CounterMixin(comptime T: type) type {
return struct {
pub fn incrementCounter(x: *T) void {
x.count += 1;
}
pub fn resetCounter(x: *T) void {
x.count = 0;
}
};
}
pub const Foo = struct {
count: u32 = 0,
pub usingnamespace CounterMixin(Foo);
};The alternative for this is based on the key observation made above:
namespacing is good, actually. The same logic can be
applied to mixins. The word "counter" in
incrementCounter and resetCounter already kind of
is a namespace in spirit—it's like how we used to have
std.ChildProcess but have since renamed it to
std.process.Child. The same idea can be applied here: what if
instead of foo.incrementCounter(), you called
foo.counter.increment()?
This can be achieved using a zero-bit field and @fieldParentPtr. Here is the above example ported to use this mechanism:
/// Mixin to provide methods to manipulate the `count` field.
pub fn CounterMixin(comptime T: type) type {
return struct {
pub fn increment(m: *@This()) void {
const x: *T = @alignCast(@fieldParentPtr("counter", m));
x.count += 1;
}
pub fn reset(m: *@This()) void {
const x: *T = @alignCast(@fieldParentPtr("counter", m));
x.count = 0;
}
};
}
pub const Foo = struct {
count: u32 = 0,
counter: CounterMixin(Foo) = .{},
};This code works just like before, except the usage is foo.counter.increment()
rather than foo.incrementCounter(). We have applied namespacing to our
mixin using zero-bit fields. In fact, this mechanism is more useful, because it allows
you to also include fields! For instance, in this case, we could move the count
field to CounterMixin. In this case that actually wouldn't be a mixin at all,
since that field is the only state CounterMixin uses—in fact, this is a
demonstration that the need for mixins is relatively rare. But in cases where a mixin is
appropriate, yet requires additional state, this approach allows using the mixin without needing
to duplicate fields at each mixin site.
async and await keywords removed §
Also removed @frameSize.
While suspend, resume, and
other machinery might remain depending on
Proposal: stackless coroutines as low-level primitives,
it is settled that there will not be async/await keywords in the language.
Instead, they will be in the Standard Library as part of the
Io Interface.
switch on non-exhaustive enums §
Switching on non-exhaustive enums now allows mixing explicit tags with the _ prong
(which represents all the unnamed values):
switch (enum_val) {
.special_case_1 => foo(),
.special_case_2 => bar(),
_, .special_case_3 => baz(),
}Additionally, it is now allowed to have both else and _:
const Enum = enum(u32) {
A = 1,
B = 2,
C = 44,
_
};
fn someOtherFunction(value: Enum) void {
// Does not compile giving "error: else and '_' prong in switch expression"
switch (value) {
.A => {},
.C => {},
else => {}, // Named tags go here (so, .B in this case)
_ => {}, // Unnamed tags go here
}
}Allow more operators on bool vectors §
Allow binary not, binary and, binary or, binary xor, and boolean not
operators on vectors of bool.
Inline Assembly: Typed Clobbers §
Until now these were stringly typed. It's kinda obvious when you think about it.
pub fn syscall1(number: usize, arg1: usize) usize {
return asm volatile ("syscall"
: [ret] "={rax}" (-> usize),
: [number] "{rax}" (number),
[arg1] "{rdi}" (arg1),
: "rcx", "r11"
);
}⬇️
pub fn syscall1(number: usize, arg1: usize) usize {
return asm volatile ("syscall"
: [ret] "={rax}" (-> usize),
: [number] "{rax}" (number),
[arg1] "{rdi}" (arg1),
: .{ .rcx = true, .r11 = true });
}To auto-upgrade, run zig fmt.
Allow @ptrCast Single-Item Pointer to Slice §
This is essentially an extension of the 0.14.0 change which allowed @ptrCast to change the length of a slice. It can now also cast from a single-item pointer to any slice, returning a slice which refers to the same number of bytes as the operand.
const std = @import("std");
test "value to byte slice with @ptrCast" {
const val: u32 = 1;
const bytes: []const u8 = @ptrCast(&val);
switch (@import("builtin").target.cpu.arch.endian()) {
.little => try std.testing.expect(std.mem.eql(u8, bytes, "\x01\x00\x00\x00")),
.big => try std.testing.expect(std.mem.eql(u8, bytes, "\x00\x00\x00\x01")),
}
}$ zig test ptrcast-single.zig 1/1 ptrcast-single.test.value to byte slice with @ptrCast...OK All 1 tests passed.
Note that in a future release, it is planned to move this functionality from @ptrCast to a new @memCast builtin, with the intention that the latter is a safer builtin which helps avoid unintentional out-of-bounds memory access. For more information, see issue #23935.
New Rules for Arithmetic on undefined §
Zig 0.15.x begins to standardise the rules around how undefined behaves in different contexts—in particular, how it behaves as an operand to arithmetic operators. In summary, only operators which can never trigger Illegal Behavior permit undefined as an operand. Any other operator will trigger Illegal Behavior (or a compile error if evaluated at comptime) if any operand is undefined.
Generally, it is always best practice to avoid any operation on undefined. If you do that, this language change, and any that follow, are unlikely to affect you. If you are affected by this language change, you might see a compile error on code which previously worked:
const a: u32 = 0;
const b: u32 = undefined;
test "arithmetic on undefined" {
// This addition now triggers a compile error
_ = a + b;
// The solution is to simply avoid this operation!
}$ zig test arith-on-undefined.zig src/download/0.15.1/release-notes/arith-on-undefined.zig:6:13: error: use of undefined value here causes illegal behavior _ = a + b; ^
Error on Lossy Coercion from Int to Float §
This compile error has always been intended, but has gone unimplemented until now. The compiler will now emit a compile error if an integer value is coerced to a float at comptime but the integer value could not be precisely represented due to floating-point precision limitations. If you encounter this, you will get a compile error like this:
test "big float literal" {
const val: f32 = 123_456_789;
_ = val;
}$ zig test lossy_int_to_float_coercion.zig src/download/0.15.1/release-notes/lossy_int_to_float_coercion.zig:2:22: error: type 'f32' cannot represent integer value '123456789' const val: f32 = 123_456_789; ^~~~~~~~~~~
The solution is typically just to change an integer literal to a floating-point literal, thereby opting in to floating-point rounding behavior:
test "big float literal" {
const val: f32 = 123_456_789.0;
_ = val;
}$ zig test lossy_int_to_float_coercion_new.zig 1/1 lossy_int_to_float_coercion_new.test.big float literal...OK All 1 tests passed.
Standard Library §
Uncategorized changes:
fs.Dir.copyFileno longer can fail witherror.OutOfMemoryfs.Dir.atomicFilenow requires awrite_bufferin the optionsfs.AtomicFilenow has aFile.Writerfield rather thanFilefieldfs.File: removedWriteFileOptions,writeFileAll,writeFileAllUnseekablein favor ofFile.Writerposix.sendfileremoved in favor offs.File.Reader.sendFile
Writergate §
All existing std.io readers and writers are deprecated in favor of the newly provided std.Io.Reader and std.Io.Writer which are non-generic and have the buffer above the vtable - in other words the buffer is in the interface, not the implementation. This means that although Reader and Writer are no longer generic, they are still transparent to optimization; all of the interface functions have a concrete hot path operating on the buffer, and only make vtable calls when the buffer is full.
These changes are extremely breaking. I am sorry for that, but I have carefully examined the situation and acquired confidence that this is the direction that Zig needs to go. I hope you will strap in your seatbelt and come along for the ride; it will be worth it.
Motivation §
Systems Distributed 2025 Talk: Don't Forget To Flush
- The old interface was generic, poisoning structs that contain them and forcing all functions to be generic as well with
anytype. The new interface is concrete.- Bonus: the concreteness removes temptation to make APIs operate directly on networking streams, file handles, or memory buffers, giving us a more reusable body of code. For example,
http.Serverafter the change no longer depends onstd.net- it operates only on streams now.
- Bonus: the concreteness removes temptation to make APIs operate directly on networking streams, file handles, or memory buffers, giving us a more reusable body of code. For example,
- The old interface passed errors through rather than defining its own set of error codes. This made errors in streams about as useful as
anyerror. The new interface carefully defines precise error sets for each function with actionable meaning. - The new interface has the buffer in the interface, rather than as a separate "BufferedReader" / "BufferedWriter" abstraction. This is more optimizer friendly, particularly for debug mode.
- The new interface supports high level concepts such as vectors, splatting, and direct file-to-file transfer, which can propagate through an entire graph of readers and writers, reducing syscall overhead, memory bandwidth, and CPU usage.
- The new interface has "peek" functionality - a buffer awareness that offers API convenience for the user as well as simplicity for the implementation.
Adapter API §
If you have an old stream and you need a new one, you can use adaptToNewApi() like this:
fn foo(old_writer: anytype) !void {
var adapter = old_writer.adaptToNewApi(&.{});
const w: *std.Io.Writer = &adapter.new_interface;
try w.print("{s}", .{"example"});
// ...
}New std.Io.Writer and std.Io.Reader API §
These ring buffers have a bunch of handy new APIs that are more convenient, perform better, and are not generic. For instance look at how reading until a delimiter works now:
while (reader.takeDelimiterExclusive('\n')) |line| {
// do something with line...
} else |err| switch (err) {
error.EndOfStream, // stream ended not on a line break
error.StreamTooLong, // line could not fit in buffer
error.ReadFailed, // caller can check reader implementation for diagnostics
=> |e| return e,
}These streams also feature some unique concepts compared with other languages' stream implementations:
- The concept of discarding when reading: allows efficiently ignoring data. For instance a decompression stream, when asked to discard a large amount of data, can skip decompression of entire frames.
- The concept of splatting when writing: this allows a logical "memset" operation to pass through I/O pipelines without actually doing any memory copying, turning an O(M*N) operation into O(M) operation, where M is the number of streams in the pipeline and N is the number of repeated bytes. In some cases it can be even more efficient, such as when splatting a zero value that ends up being written to a file; this can be lowered as a seek forward.
- Sending a file when writing: this allows an I/O pipeline to do direct fd-to-fd copying when the operating system supports it.
- The stream user provides the buffer, but the stream implementation decides the minimum buffer size. This effectively moves state from the stream implementation into the user's buffer
std.fs.File.Reader and std.fs.File.Writer §
std.fs.File.Reader memoizes key information about a file handle such as:
- The size from calling stat, or the error that occurred therein.
- The current seek position.
- The error that occurred when trying to seek.
- Whether reading should be done positionally or streaming.
- Whether reading should be done via fd-to-fd syscalls (e.g.
sendfile)
versus plain variants (e.g.read).
Fulfills the std.Io.Reader interface.
This API turned out to be super handy in practice. Having a concrete type to pass around that memoizes file size is really nice. Most code that previously was calling seek functions on a file handle should be updated to operate on this API instead, causing those seeks to become no-ops thanks to positional reads, while still supporting a fallback to streaming reading.
std.fs.File.Writer is the same idea but for writing.
Upgrading std.io.getStdOut().writer().print() §
Please use buffering! And don't forget to flush!
var stdout_buffer: [1024]u8 = undefined;
var stdout_writer = std.fs.File.stdout().writer(&stdout_buffer);
const stdout = &stdout_writer.interface;
// ...
try stdout.print("...", .{});
// ...
try stdout.flush();reworked std.compress.flate §

std.compress API restructured everything to do with flate, which includes zlib and gzip.
std.compress.flate.Decompress is your main API now and it has a container parameter.
New API example:
var decompress_buffer: [std.compress.flate.max_window_len]u8 = undefined;
var decompress: std.compress.flate.Decompress = .init(reader, .zlib, &decompress_buffer);
const decompress_reader: *std.Io.Reader = &decompress.reader;If decompress_reader will be piped entirely to a particular *Writer, then give it an empty buffer:
var decompress: std.compress.flate.Decompress = .init(reader, .zlib, &.{});
const n = try decompress.streamRemaining(writer);Compression functionality was removed. Sorry, you will have to copy the old code into your application, or use a third party package.
It will be nice to get deflate back into the Zig standard library, but for now, progressing the language takes priority over progressing the standard library, and this change is on the path towards locking in the final language design with respect to I/O as an Interface.
Some notable factors:
- New implementation does not calculate a checksum since it can be done out-of-band.
- New implementation has the fancy match logic replaced with a naive
forloop. In the future it would be nice to add a memory copying utility for this that zstd would also use. Despite this, the new implementation performs roughly 10% better in an untar implementation, while reducing compiler code size by 2%. #24614
CountingWriter Deleted §
- If you were discarding the bytes, use
std.Io.Writer.Discarding, which has a count. - If you were allocating the bytes, use
std.Io.Writer.Allocating, since you can check how much was allocated. - If you were writing to a fixed buffer, use
std.Io.Writer.fixed, and then check theendposition. - Otherwise, try not to create an entire node in the stream graph solely for counting bytes. It's very disruptive to optimal buffering.
BufferedWriter Deleted §
const stdout_file = std.fs.File.stdout().writer();
var bw = std.io.bufferedWriter(stdout_file);
const stdout = bw.writer();
try stdout.print("Run `zig build test` to run the tests.\n", .{});
try bw.flush(); // Don't forget to flush!⬇️
var stdout_buffer: [4096]u8 = undefined;
var stdout_writer = std.fs.File.stdout().writer(&stdout_buffer);
const stdout = &stdout_writer.interface;
try stdout.print("Run `zig build test` to run the tests.\n", .{});
try stdout.flush(); // Don't forget to flush!Consider making your stdout buffer global.
"{f}" Required to Call format Methods §
Turn on -freference-trace to help you find all the format string breakage.
Example:
std.debug.print("{}", .{std.zig.fmtId("example")});This will now cause a compile error:
error: ambiguous format string; specify {f} to call format method, or {any} to skip it
Fixed by:
std.debug.print("{f}", .{std.zig.fmtId("example")});Motivation: eliminate these two footguns:
Introducing a format method to a struct caused a bug if there was formatting code somewhere that prints with {} and then starts rendering differently.
Removing a format method to a struct caused a bug if there was formatting code somewhere that prints with {} and is now changed without notice.
Now, introducing a format method will cause compile errors at all {} sites. In the future, it will have no effect.
Similarly, eliminating a format method will not change any sites that use {}.
Using {f} always tries to call a format method, causing a compile error if none exists.
Format Methods No Longer Have Format Strings or Options §
pub fn format(
this: @This(),
comptime format_string: []const u8,
options: std.fmt.FormatOptions,
writer: anytype,
) !void { ... }⬇️
pub fn format(this: @This(), writer: *std.Io.Writer) std.Io.Writer.Error!void { ... }The deleted FormatOptions are now for numbers only.
Any state that you got from the format string, there are three suggested alternatives:
- different format methods
pub fn formatB(foo: Foo, writer: *std.Io.Writer) std.Io.Writer.Error!void { ... }This can be called with "{f}", .{std.fmt.alt(Foo, .formatB)}.
std.fmt.Alt
pub fn bar(foo: Foo, context: i32) std.fmt.Alt(F, F.baz) {
return .{ .data = .{ .context = context } };
}
const F = struct {
context: i32,
pub fn baz(f: F, writer: *std.Io.Writer) std.Io.Writer.Error!void { ... }
};This can be called with "{f}", .{foo.bar(1234)}.
- return a struct instance that has a format method, combined with
{f}.
pub fn bar(foo: Foo, context: i32) F {
return .{ .context = 1234 };
}
const F = struct {
context: i32,
pub fn format(f: F, writer: *std.Io.Writer) std.Io.Writer.Error!void { ... }
};This can be called with "{f}", .{foo.bar(1234)}.
Formatted Printing No Longer Deals with Unicode §
If you were relying on alignment combined with Unicode codepoints, it is now ASCII/bytes only. The previous implementation was not fully Unicode-aware. If you want to align Unicode strings you need full Unicode support which the standard library does not provide.
New Formatted Printing Specifiers §
- {t} is shorthand for
@tagName()and@errorName() - {d} and other integer printing can be used with custom types which calls
formatNumbermethod. - {b64}: output string as standard base64
De-Genericify Linked Lists §
With these changes, there's no longer any incentive to hand-roll next/prev pointers. A little bit less bloat too.
Migration guide:
std.DoublyLinkedList(T).Node⬇️
struct {
node: std.DoublyLinkedList.Node,
data: T,
}Then use @fieldParentPtr to get from node to data.
In many cases there's a better pattern instead which is to put the node intrusively into the data structure. If you're not already doing that, there's a good chance linked list is the wrong data structure.
std.Progress supports progress bar escape codes §
Turns out there are escape codes for sending progress status to the terminal.
It integrates with --watch in the Build System to set error state when
failures occur, and clear it when they are fixed, also to clear progress
when waiting for user input.
std.Progress gains a setStatus function and the following enum:
pub const Status = enum {
/// Indicates the application is progressing towards completion of a task.
/// Unless the application is interactive, this is the only status the
/// program will ever have!
working,
/// The application has completed an operation, and is now waiting for user
/// input rather than calling exit(0).
success,
/// The application encountered an error, and is now waiting for user input
/// rather than calling exit(1).
failure,
/// The application encountered at least one error, but is still working on
/// more tasks.
failure_working,
};HTTP Client and Server §
These APIs and implementations have been completely reworked.
Server API no longer depends on std.net. Instead, it only depends on
std.Io.Reader and std.Io.Writer. It also has all
the arbitrary limitations removed. For instance, there is no longer a limit
on how many headers can be sent.
var read_buffer: [8000]u8 = undefined;
var server = std.http.Server.init(connection, &read_buffer);⬇️
var recv_buffer: [4000]u8 = undefined;
var send_buffer: [4000]u8 = undefined;
var conn_reader = connection.stream.reader(&recv_buffer);
var conn_writer = connection.stream.writer(&send_buffer);
var server = std.http.Server.init(conn_reader.interface(), &conn_writer.interface);Server and Client both share std.http.Reader and std.http.BodyWriter which
again only depends on I/O streams and not networking.
Client upgrade example:
var server_header_buffer: [1024]u8 = undefined;
var req = try client.open(.GET, uri, .{
.server_header_buffer = &server_header_buffer,
});
defer req.deinit();
try req.send();
try req.wait();
const body_reader = try req.reader();
// read from body_reader...
var it = req.response.iterateHeaders();
while (it.next()) |header| {
_ = header.name;
_ = header.value;
}⬇️
var req = try client.request(.GET, uri, .{});
defer req.deinit();
try req.sendBodiless();
var response = try req.receiveHead(&.{});
// Once we call reader() below, strings inside `response.head` are invalidated.
var it = response.head.iterateHeaders();
while (it.next()) |header| {
_ = header.name;
_ = header.value;
}
// Optimal size depends on how you will use the reader.
var reader_buffer: [100]u8 = undefined;
const body_reader = response.reader(&reader_buffer);TLS Client §
std.crypto.tls.Client no longer depends on std.net or std.fs. Instead, it only
depends on std.Io.Reader and std.Io.Writer.
ArrayList: make unmanaged the default §
std.ArrayList->std.array_list.Managedstd.ArrayListAligned->std.array_list.AlignedManaged
Warning: these will both eventually be removed entirely.
Having an extra field is more complicated than not having an extra field, so not having it is the null hypothesis. What pattern does having an allocator field allow that not having one doesn't?
- avoiding accidentally using the wrong allocator
- convenience when you need to pass an allocator also
But there are downsides:
- worse method function signatures in the face of reservations
- inability to statically initialize
- extra memory storage cost, particularly for nested containers
The reasoning goes like this: the upsides are not worth the downsides. Also, given that the correct allocator is always handy, and incorrect use can be trivially safety-checked, the simplicity of only having one implementation is quite valuable compared to the convenience that is gained by having a second implementation.
In practice, this has not been a controversial change with experienced Zig users.
Ring Buffers §
There are too many ring buffer implementations in the standard library!
std.fifo.LinearFifo is removed due to being poorly designed. This data structure was
unnecessarily generic due to accepting a comptime enum parameter that determined whether
its buffer was heap-allocated with an Allocator parameter, passed in as an externally-owned slice,
or stored in the struct itself. Each of these different buffer management strategies
describes a fundamentally different data structure.
Furthermore, most of its real-world use cases are subsumed by New std.Io.Writer and std.Io.Reader API which are both ring buffers.
Similarly, std.RingBuffer is removed since it was only used by the zstd implementation which
has been upgraded to use New std.Io.Writer and std.Io.Reader API.
There was also std.compress.flate.CircularBuffer which was internal to the flate implementation;
now deleted.
There was also one each in HTTP Client and Server - again deleted in favor of New std.Io.Writer and std.Io.Reader API.
Even with all five of these deletions, these things pop up like whack-a-mole. Here are some more ring buffers that have been spotted:
lib/std/compress/lzma/decode/lzbuffer.zig- internal to lzma implementation.lib/std/crypto/tls.zig- made redundant with std.Io.Reader.lib/std/debug/FixedBufferReader.zig- made redundant by std.Io.Reader's excellent Debug mode performance.- this random pull request - nice try, you almost got away with it!!
Jokes aside, there will likely be room for a general-purpose, reusable ring buffer implementation in
the standard library, however, first ask yourself if what you really need is std.Io.Reader
or std.Io.Writer.
Removal of BoundedArray §
This data structure was popular due to being trivially copyable. However, such convenience comes at a cost.
To upgrade, categorize code based on where the limit comes from:
- Is it an arbitrary limit for which the BoundedArray usage is making a reasonable guess at the upper bound, or deciding resource limits? Don't guess. Don't make that choice for the calling code. Accept a buffer as a slice as an input, or use dynamic allocation. (example: the markdown code in #24699)
- Is it type safety around a stack buffer? Just use ArrayListUnmanaged. It's fine. It's actually really convenient that this same data structure works here. (example: test_switch_dispatch_loop.zig in #24699)
std.ArrayList now has "Bounded" variants of all the "AssumeCapacity" methods:
var stack = try std.BoundedArray(i32, 8).fromSlice(initial_stack);⬇️
var buffer: [8]i32 = undefined;
var stack = std.ArrayListUnmanaged(i32).initBuffer(&buffer);
try stack.appendSliceBounded(initial_stack);- Is it an ordered set with a well-defined maximum capacity? Quite rare. Just free-code it. (example: changes to Zcu.zig in #24699)
- Is it being used as a growable array that can be copied? This wastes time copying undefined memory all over the place and causes unnecessary generic code bloat.
Deletions and Deprecations §
- std.fs.File.reader -> std.fs.File.deprecatedReader
- std.fs.File.writer -> std.fs.File.deprecatedWriter
- std.fmt.fmtSliceEscapeLower -> std.ascii.hexEscape
- std.fmt.fmtSliceEscapeUpper -> std.ascii.hexEscape
- std.zig.fmtEscapes -> std.zig.fmtString
- std.fmt.fmtSliceHexLower -> {x}
- std.fmt.fmtSliceHexUpper -> {X}
- std.fmt.fmtIntSizeDec -> {B}
- std.fmt.fmtIntSizeBin -> {Bi}
- std.fmt.fmtDuration -> {D}
- std.fmt.fmtDurationSigned -> {D}
- std.fmt.Formatter -> std.fmt.Alt
- now takes context type explicitly
- no fmt string
- std.fmt.format -> std.Io.Writer.print
- std.io.GenericReader -> std.Io.Reader
- std.io.GenericWriter -> std.Io.Writer
- std.io.AnyReader -> std.Io.Reader
- std.io.AnyWriter -> std.Io.Writer
- deleted
std.io.SeekableStream- Instead, use
*std.fs.File.Reader,*std.fs.File.Writer, orstd.ArrayListUnmanagedconcrete types, because the implementations will be fundamentally different based on whether you are operating on files or memory.
- Instead, use
- deleted
std.io.BitReader- Bit reading should not be abstracted at this layer; it just makes your hot loop harder to optimize. Tightly couple this code with your stream implementation.
- deleted
std.io.BitWriter- ditto
- deleted
std.Io.LimitedReader - deleted
std.Io.BufferedReader - deleted
std.fifo
Build System §
Uncategorized changes:
zig build: print newline before build summary
Removed Deprecated Implicit Root Module §
Zig 0.14.0 introduced the root_module field to std.Build.ExecutableOptions and friends, deprecating the old fields which defined the root module like root_source_file. Zig 0.15.x removes the deprecated fields. If you did not migrate in the previous release cycle, you will encounter compile errors such as this one:
pub fn build(b: *std.Build) void {
const exe = b.addExecutable(.{
.name = "foo",
.root_source_file = b.path("src/main.zig"),
.target = b.graph.host,
.optimize = .Debug,
});
b.installArtifact(exe);
}
test {
_ = &build;
}
const std = @import("std");$ zig test deprecated-addExecutable.zig src/download/0.15.1/release-notes/deprecated-addExecutable.zig:4:10: error: no field named 'root_source_file' in struct 'Build.ExecutableOptions' .root_source_file = b.path("src/main.zig"), ^~~~~~~~~~~~~~~~ /home/ci/deps/zig-x86_64-linux-0.15.2/lib/std/Build.zig:771:31: note: struct declared here pub const ExecutableOptions = struct { ^~~~~~ referenced by: test_0: src/download/0.15.1/release-notes/deprecated-addExecutable.zig:12:10
For this change's migration path, please see the corresponding section of the Zig 0.14.0 release notes.
macOS File System Watching §
The --watch flag to zig build is now supported on macOS. In Zig 0.14.0, the flag was accepted, but unfortunately behaved incorrectly with most editors. In Zig 0.15.x, this functionality has been rewritten on macOS to use the File System Events API for fast and reliable file system update watching.
So, if you were avoiding --watch in previous Zig versions due to the macOS bug, you can now use it safely. This is particularly useful if you are interested in trying Incremental Compilation, since the typical way to use that feature today involves passing the flags --watch -fincremental to zig build.
Web Interface and Time Report §
Zig 0.14.0 included an experimental web interface for the work-in-progress built-in fuzzer. In this version, that interface has been replaced with a more general web interface for the build system in general. This interface can be exposed using zig build --webui. When this option is passed, the zig build process will continue running even after the build completes.
The web interface is, by itself, relatively uninteresting: it merely shows the list of build steps and information about which are in progress, and has a button to manually trigger a rebuild (hence giving a possible alternative to the zig build --watch workflow). If --fuzz is passed to zig build, it also exposes the Fuzzer interface, which is mostly unchanged from 0.14.0.
However, the web interface also exposes a new feature known as "time reports". By passing the new --time-report option to zig build, the web interface will include expandable information about the time taken to evaluate every step in the graph. In particular, any std.Build.Step.Compile in the graph will be associated with detailed information about which parts of the Zig compiler pipeline were fast and slow, and which individual files and declarations took the most time to semantically analyze, generate machine code for, and link into the binary.
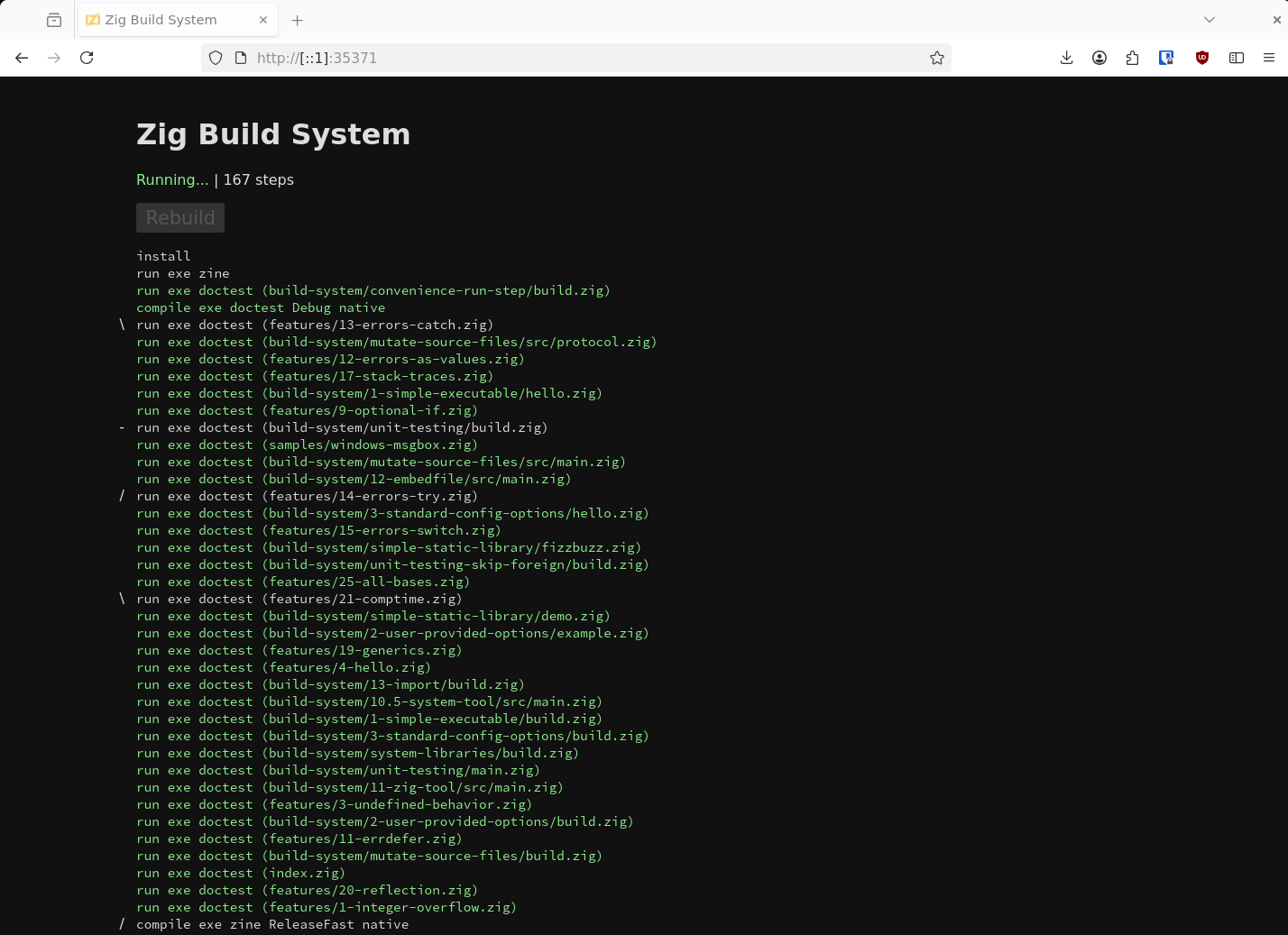
This is a relatively advanced feature, but it can be very useful for determining parts of your code which are needlessly slowing down compilation, by opening the "Declarations" table and viewing the first few rows.
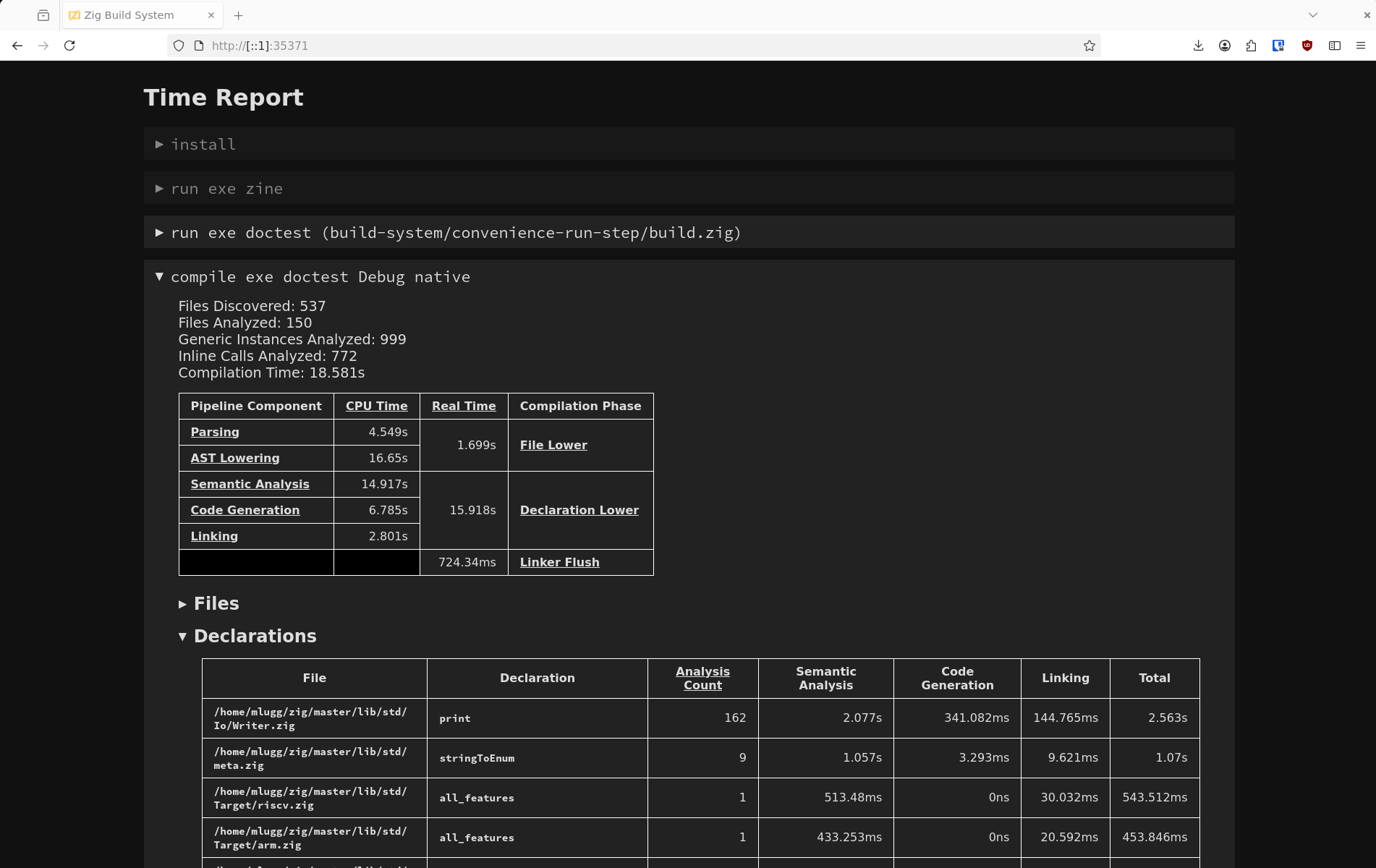
LLVM pass timing information is also provided if the LLVM backend was used for the compilation.
Compiler §
x86 Backend §

Zig 0.15.x enables Zig's self-hosted x86_64 code generation backend by default in Debug mode.
More specifically, this backend is now the default when targeting x86_64 in Debug mode, except on NetBSD, OpenBSD, and Windows, where the LLVM backend is still the default due to Linker deficiencies.
When this backend is selected, you will begin to reap the benefits of the investments the Zig project has made over the past few years. Compilation time is significantly improved—around a 5x decrease compared to LLVM in most cases. This is only the beginning; the self-hosted x86_64 backend has been built to support Incremental Compilation, which will result in another extreme speed-up when it is stable enough to be enabled by default. Fast compilation is a key goal of the Zig project, and one we have been quietly making progress on for years—this release sees those efforts starting to come to fruition.
Using the self-hosted x86 backend also means you are not subject to the effects of upstream LLVM bugs, of which we are currently tracking over 60. In fact, the self-hosted x86 backend already passes a larger subset of our "behavior test suite" than the LLVM backend does (1984/2008 vs 1977/2008). In other words, this backend provides a more complete and correct implementation of the Zig language.
Of course, the self-hosted x86 backend does currently have some deficiencies and bugs of its own. If you are affected by any of these issues, you can use LLVM backend for Debug builds by passing -fllvm on the command-line or by setting .use_llvm = true when creating a std.Build.Step.Compile. The self-hosted x86 backend is also currently known to emit slower machine code than the LLVM backend.
But in most cases, the self-hosted backend is now a better choice for development. For instance, the Zig core team have been building the Zig compiler almost exclusively with the self-hosted x86 backend instead of LLVM for quite a while. This has been a serious improvement to our workflows, with the Zig compiler building in just a few seconds rather than 1-2 minutes. You can now expect to see similar improvements to your own development experience.
aarch64 Backend §
Having improved the self-hosted x86 Backend enough for it to be enabled by default, Jacob has set his eyes on a new target: aarch64. This architecture is growing in popularity, particularly since modern Apple hardware is based on it. Therefore, aarch64 is the Zig project's next big focus for self-hosted code generation without LLVM.
For this work-in-progress backend, Jacob has been able to take the lessons learnt from the x86 backend to explore new design directions. It's too early to be sure, but we expect that the new design will improve both compiler performance (being even faster than the self-hosted x86_64 backend) and the quality of emitted machine code, with the ultimate goal of becoming competitive with LLVM's codegen quality in Debug mode. This devlog has some more details.
This backend is passing 1656/1972 (84%) behavior tests relative to LLVM, so is not ready to be enabled by default, nor is it currently usable in any real use case. However, it is making rapid progress, and is expected to become the default for Debug mode in a future release.
Our work on self-hosted code generation backends is a part of our long-term plan to transition LLVM to an optional dependency and decouple it from the compiler implementation. Achieving this goal will lead to large decreases in compile time, good support for incremental compilation in Debug builds, and could even allow us to explore language features which LLVM cannot lower effectively.
Incremental Compilation §
Zig 0.15.x makes further progress on the work-in-progress Incremental Compilation functionality, which allows the compiler to perform very fast rebuilds by only re-compiling code which has changed. Various bugs have been fixed, particularly relating to changing file imports.
This feature is still experimental—it has known bugs and can lead
to miscompilations or incorrect compile errors. However, it is now stable
enough to be used reliably in combination with -fno-emit-bin.
If you have a large project that does not compile instantly, you should be taking advantage of
--watch combined with -fincremental and
-Dno-bin for compile errors. Seriously, it's really
good. Please chat with someone if you have trouble figuring out how to
expose -Dno-bin from your build script.
The next release cycle will continue to make progress towards enabling Incremental Compilation by default. In the meantime, if you are interested in trying this experimental feature, take a look at #21165.
Threaded Codegen §
The Zig compiler is designed to be parallelized, so that different pieces of compilation work can run in parallel with one another to improve compiler performance. In the past the Zig compiler was largely single-threaded, but 0.14.0 introduced the ability for certain compiler backends to run in parallel with the frontend (Semantic Analysis). Zig 0.15.x continues down this path by allowing Semantic Analysis, Code Generation, and Linking to all happen in parallel with one another. Code Generation in particular can itself be split across arbitrarily many threads.
Compared to 0.14.0, this typically leads to another performance boost when using self-hosted backends such as the x86 Backend. The improvement in wall-clock time varies from relatively insignificant to upwards of 50% depending on the specific code being compiled. However, as one real-world data point, building the Zig compiler using its own x86_64 backend got 27% faster on one system from this change, with the wall-clock time going from 13.8s to 10.0s.
This devlog looks a little more closely at this change, but in short, you can expect better compiler performance when using self-hosted backends thanks to this parallelization. Oh, and you get more detailed progress information too.
Allow configuring UBSan mode at the module level §
The Zig CLI and build system now allow more control over the UBSan mode. zig build-exe and friends accept -fsanitize-c=trap and -fsanitize-c=full, with the old -fsanitize-c spelling being equivalent to the latter.
- With
full, the UBSan runtime is built and linked into the program, resulting in better error messages when undefined behavior is triggered, at the cost of code size. - With
trap, trap instructions are inserted instead, resulting inSIGILLwhen undefined behavior is triggered, but smaller code size.
If no flag is given, the default depends on the build mode.
For zig cc, in addition to the existing -fsanitize=undefined, -fsanitize-trap=undefined is now also understood and is generally equivalent to -fsanitize-c=trap for zig build-exe.
Due to this change, the sanitize_c field in the std.Build API had to have its type changed from ?bool to ?std.zig.SanitizeC. If you were setting this field to true or false previously, you'll now want .full or .off, respectively, to get the same behavior.
Compile Tests to Object File §
Typically, Zig's testing functionality is used to build an executable directly. However, there are situations in which you may want to build tests without linking them into a final executable, such as for integration with external code which loads your application as a shared library. Zig 0.15.x facilitates such use cases by allowing an object file to be emitted instead of a binary, and this object can then be linked however is necessary.
On the CLI, this is represented by running zig test-obj instead of zig test.
When using the build system, it is represented through a new std.Build API. By passing the emit_object option to std.Build.addTest, you get a Step.Compile which emits an object file, which you can then use that as you would any other object. For instance, it can be installed for external use, or it can be directly linked into another step. However, note that when using this feature, the build runner does not communicate with the test runner, falling back to the default zig test behavior of reporting failed tests over stderr. Users of this feature will likely want to override the test runner for the compilation as well, replacing it with a custom one which communicates with some external test harness.
Zig Init §
The zig init command has a new template for creating projects.
The old template included code for generating a static library of a Zig module, which caused some newcomers to mistakenly think that this was the preferred way of sharing reusable Zig code.
The new template offers boilerplate for creating a Zig module and an executable. This should cover most use cases, and it also shows how to split logic between a reusable module and the application. Users that only intend to create one kind of artifact can delete the extra code, although the template should be considered a gentle reminder about:
- creating tooling for your libraries
- providing convenient access to reusable logic in your executables
You can now pass --minimal or -m to zig init
to generate a minimalistic template. Running the command will generate a
build.zig.zon file and, if not already present, a
build.zig file with just a stub of the build function.
This option is intended for those who are familiar with the Zig build system,
and who mainly want a convenient way of generating a Zon file with a correct
fingerprint.
Linker §
Zig's linker received only bug fixes and maintenance during this release cycle. However, it will be a key focus in the next release cycle in order to improve Incremental Compilation.
Fuzzer §
Although the core team remains enthusiastic about fuzzing, we did not find the time to actively push forward on it during this release cycle. We'd like to acknowledge the efforts of contributor Kendall Condon who opened a pull request greatly improve capabilities of the fuzzer, and is patiently waiting for collaboration from the core team.
Bug Fixes §
Full list of the 201 bug reports closed during this release cycle.
Many bugs were both introduced and resolved within this release cycle. Most bug fixes are omitted from these release notes for the sake of brevity.
This Release Contains Bugs §

Zig has known bugs, miscompilations, and regressions.
Even with Zig 0.15.x, working on a non-trivial project using Zig may require participating in the development process.
When Zig reaches 1.0.0, Tier 1 support will gain a bug policy as an additional requirement.
Toolchain §
LLVM 20 §
This release of Zig upgrades to
LLVM 20.1.8. This
covers Clang (zig cc/zig c++), libc++, libc++abi, libunwind, and
libtsan as well.
Zig now allows using LLVM's SPIR-V backend. Note that the self-hosted
SPIR-V backend remains the default. To use the LLVM backend, build with
-fllvm.
Support dynamically-linked FreeBSD libc when cross-compiling §
Zig now allows cross-compiling to FreeBSD 14+ by providing stub libraries for dynamic libc, similar to how cross-compilation for glibc is handled. Additionally, all system and libc headers are provided.
Support dynamically-linked NetBSD libc when cross-compiling §
Zig now allows cross-compiling to NetBSD 10.1+ by providing stub libraries for dynamic libc, similar to how cross-compilation for glibc is handled. Additionally, all system and libc headers are provided.
glibc 2.42 §
glibc version 2.42 is now available when cross-compiling.
Allow linking native glibc statically §
Zig now permits linking against native glibc statically. This is not generally a good idea, but can be fine in niche use cases that don't rely on glibc functionality which internally requires dynamic linking (for things such as NSS and iconv).
Note that this does not apply when cross-compiling using Zig's bundled glibc as Zig only provides dynamic glibc.
MinGW-w64 §
This release bumps the bundled MinGW-w64 copy to commit
38c8142f660b6ba11e7c408f2de1e9f8bfaf839e.
zig libc §
In this release, we've started the effort to share code between the statically-linked libcs that Zig provides—currently musl, wasi-libc, and MinGW-w64—by reimplementing common functions in Zig code in the new zig libc library. This means that there is a single canonical implementation of each function, and we're able to improve the implementation without having to modify the vendored libc code from the aforementioned projects. The very long term aspiration here—which will require a lot of work—is to completely eliminate our dependency on the upstream C implementation code of those libcs, such that we ship only their headers.
This effort is contributor-friendly, so if this sounds interesting to you, check out issue #2879 for details.
zig cc §
zig cc now properly respects the -static and -dynamic flags. Most notably, this allows statically linking native glibc, and dynamically linking cross-compiled musl.
zig objcopy regressed §
Sorry, the code was not up to quality standards and must be reworked. Some functionality remains; other functionality errors with "unimplemented". #24522
Roadmap §

The two major themes of the 0.16.0 release cycle will be async I/O and aarch64 backend.
Some upcoming milestones we will be working towards:
- Introducing I/O as an Interface
- Making the aarch64 Backend the default backend for debug mode.
- Enhance Linker implementations, eliminating dependency on LLD and supporting Incremental Compilation.
- Enhance the integrated Fuzzer to be competitive with AFL and other state-of-the-art fuzzers.
I/O as an Interface §
Moving forward, Zig will rearrange all of its file system, networking,
timers, synchronization, and pretty much everything that can block into a new std.Io interface.
All code that performs I/O will need access to an Io instance, similar to how
all code that allocates memory needs access to an Allocator instance.
This will make it possible to write optimal, reusable packages that are agnostic to the application's concurrency model, express asynchrony, catch more kinds of bugs, and make event loops first class citizens in the Zig ecosystem.
Thank You Contributors! §

Here are all the people who landed at least one contribution into this release:
- Alex Rønne Petersen
- Andrew Kelley
- Matthew Lugg
- Jacob Young
- Ali Cheraghi
- Justus Klausecker
- Pat Tullmann
- Ryan Liptak
- David Rubin
- Linus Groh
- Carl Åstholm
- Pavel Verigo
- Techatrix
- Dominic
- Igor Anić
- Carmen
- Casey Banner
- Lewis Gaul
- Elaine Gibson
- Frank Denis
- Isaac Freund
- Kendall Condon
- samy007
- Bingwu Zhang
- Ian Johnson
- Loris Cro
- Alex Kladov
- Mason Remaley
- Meghan Denny
- tjog
- David Senoner
- IOKG04
- Jonathan Marler
- Koki Ueha
- Robin Voetter
- Shun Sakai
- xdBronch
- 孙冰
- HydroH
- Marc Tiehuis
- Rue
- Silver
- Stefan Weigl-Bosker
- Stephen Gregoratto
- Wooster
- antlilja
- Brandon Black
- Carter Snook
- Chinmay Dalal
- Dacheng Gao
- Daniel Kongsgaard
- Felix Rabe
- Giuseppe Cesarano
- Ivan Stepanov
- Jackson Wambolt
- Jan200101
- John Benediktsson
- KNnut
- LN Liberda
- Manlio Perillo
- Michael Pfaff
- Misaki Kasumi
- Parker Liu
- SuperAuguste
- Veikka Tuominen
- Will Lillis
- kj4tmp
- psbob
- taylor.fish
- ziggoon
- Андрей Краевский
- 190n
- A cursed quail
- Alexandre
- Alexandre Blais
- Andrew Barchuk
- Anton Serov
- Arnau Camprubí
- AsmArtisan256
- Atlas Yu
- Auguste Rame
- BreadTom
- Bryson Miller
- Cezary Kupaj
- Chris Boesch
- Chris Clark
- Cutie Deng
- David John
- Deatil
- DialecticalMaterialist
- Dimitris Dinodimos
- Dongjia Zhang
- DubbleClick
- Elijah M. Immer
- Eric Joldasov
- Erik Schlyter
- Evan Silberman
- Felix "xq" Queißner
- Felix Koppe
- Fri3dNstuff
- GalaxyShard
- GasInfinity
- Giuseppe Cesarano
- Gungun974
- Hilger Baumstark
- Jeremy Hertel
- Jonathan Gautheron
- Joost Doornbos
- Josh Wolfe
- Kevin Boulain
- Kevin Primm
- Kiëd Llaentenn
- Krzysztof Wolicki
- Kurt Wagner
- Kuwazy
- Luis Cáceres
- Maksat
- Marc
- Marcos Gutiérrez Alonso
- Mathias Lafeldt
- Matthew Roush
- Micah Switzer
- Mun Maks
- Nameless
- Pavel Otchertsov
- PlayDay
- Pratham
- Roman Frołow
- Ryan King
- Rémy Mathieu
- Sean Stasiak
- Seiichi Uchida
- Simon Brown
- Super User
- TCROC
- TibboddiT
- Tobias Simetsreiter
- Travis Staloch
- Tristan Ross
- Vadzim Dambrouski
- Xavier Bouchoux
- Zenomat
- Ziyi Yan
- blurrycat
- dan
- fardragon
- g-logunov
- godalming123
- homersimpsons
- imreallybadatnames™️
- jaune
- lumanetic
- massi
- mikastiv
- mochalins
- oittaa
- phatchman
- remeh
- rpkak
- sdzx-1
- triallax
- Özgür Akkurt
Thank You Sponsors! §

Special thanks to those who sponsor Zig. Because of diverse, recurring donations, Zig is driven by the open source community, rather than the goal of making profit. In particular, those below sponsor Zig for $50/month or more:
- Josh Wolfe
- Matt Knight
- Stevie Hryciw
- Jethro Nederhof
- Karrick McDermott
- José M Rico
- Andrew Mangogna
- drfuchs
- Joran Dirk Greef
- Rui Ueyama
- bfredl
- Emi
- Derek Collison
- Daniele Cocca
- Christopher Dolan
- Rafael Batiati
- Aras Pranckevičius
- Terin Stock
- Kirk Scheibelhut
- Brian Gold
- Paul Harrington
- Clark Gaebel
- Bun
- Marcus Eagan
- Ken Chilton
- Will Manning
- Spiral
- Alok Parlikar
- Huly® Platform™
- marximimus
- Numan
- Reuben Dunnington
- Isaac Yonemoto
- Auguste Rame
- Jay Petacat
- Dirk de Visser
- Santiago Andaluz
- Yaroslav Zhavoronkov
- Chris Heyes
- James McGill
- Luke Champine
- AG.王爱国
- Wojtek Mach
- Daniel Hensley
- Erik Mållberg
- Fabio Arnold
- Ross Rheingans-Yoo
- 🇺🇦 Mykhailo Tsiuptsiun
- Kiril Mihaylov
- Brett Slatkin
- Sean Carey
- Alex Rønne Petersen
- Yurii Rashkovskii
- OM PropTech GmbH
- Lucas
- Alex Sergeev
- Josh Ashby
- Chris Baldwin
- Malcolm Still
- Francis Bouvier
- Fawzi Mohamed
- Ian Johnson
- Carlos Pizano Uribe
- Anita SV
- Rene Schallner
- Linus Groh
- Jinkyu Yi
- Jake Hemmerle
- Will Pragnell
- Peter Snelgrove
- Jeff Fowler
- Leo Razoumov
- Julien Debache
- Christian Gibson
- Kohei Nozaki
- Dylan Conway
- Hlib Kanunnikov
- Viktor Tratsevskyy
- Miguel Filipe
- merkleplant
- Duncan Marsh
- Roast Beef Kazenzakis
- Willian Hasse
- daily.dev
- Sonic
- Matteo De Wint
- Matteias Collet
- smallkirby
- Stefan Hagen
- Miles J McGruder
- Álvaro Justen
- Laaman03
- Paul Horn
- datsteves
- MiahDrao97
- Kirill Andriianov