0.12.0 Release Notes

Zig is a general-purpose programming language and toolchain for maintaining robust, optimal, and reusable software.
Zig development is funded via Zig Software Foundation, a 501(c)(3) non-profit organization. Please consider a recurring donation so that we can offer more billable hours to our core team members. This is the most straightforward way to accelerate the project along the Roadmap to 1.0.
This release features 8 months of work: changes from 268 different contributors, spread among 3688 commits.
In the past, these release notes have been extremely long, attempting to take note of all enhancements that occurred during the release cycle. In the interest of not overwhelming the reader as well as the maintainers creating these notes, this document is abridged. Many changes, including API breaking changes, are not mentioned here.
Table of Contents §
- Table of Contents
- Support Table
- Redesign How Autodoc Works
- Language Changes
- Standard Library
- Windows Command Line Argument Parsing
- Bring-Your-Own-OS API Layer Regressed
- std.os renamed to std.posix
- Ryu Floating-Point Formatting
- Reworked HTTP
- deflate reimplemented from first principles
- std.posix APIs Gain Type Safety
- std.builtin Enum Fields Lowercased
- Global Configuration
- Pointer Stability Locks
- Build System
- Compiler
- Windows Resources
- Linker
- Cache System
- Bug Fixes
- Toolchain
- Roadmap
- Thank You Contributors!
- Thank You Sponsors!
Support Table §
Tier System §
A green check mark (✅) indicates the target meets all the requirements for the support tier. The other icons indicate what is preventing the target from reaching the support tier. In other words, the icons are to-do items. If you find any wrong data here please submit a pull request!
Tier 1 Support §
- Not only can Zig generate machine code for these targets, but the Standard Library cross-platform abstractions have implementations for these targets.
- The CI server automatically tests these targets on every commit to master branch. The 🧪 icon means this target does not yet have CI test coverage.
- The CI server automatically produces pre-built binaries for these targets, on every commit to master, and updates the download page with links. The 📦 icon means the download page is missing this target.
- These targets have debug info capabilities and therefore produce stack traces on failed assertions.
- libc is available for this target even when cross compiling.
- All the behavior tests and applicable standard library tests pass for this target. All language features are known to work correctly. Experimental features do not count towards disqualifying an operating system or architecture from Tier 1. The 🐛 icon means there are known bugs preventing this target from reaching Tier 1.
- zig cc, zig c++, and related toolchain commands support this target.
- If the Operating System is proprietary then the target is not marked deprecated by the vendor. The 💀 icon means the OS is officially deprecated, such as macos/x86.
| freestanding | Linux 3.16+ | macOS 11+ | Windows 10+ | WASI | |
|---|---|---|---|---|---|
| x86_64 | ✅ | ✅ | ✅ | ✅ | N/A |
| x86 | ✅ | #1929 🐛 | 💀 | #537 🐛 | N/A |
| aarch64 | ✅ | #2443 🐛 | ✅ | #16665 🐛 | N/A |
| arm | ✅ | #3174 🐛 | 💀 | 🐛📦🧪 | N/A |
| mips | ✅ | #3345 🐛📦 | N/A | N/A | N/A |
| riscv64 | ✅ | #4456 🐛 | N/A | N/A | N/A |
| sparc64 | ✅ | #4931 🐛📦🧪 | N/A | N/A | N/A |
| powerpc64 | ✅ | 🐛 | N/A | N/A | N/A |
| powerpc | ✅ | 🐛 | N/A | N/A | N/A |
| wasm32 | ✅ | N/A | N/A | N/A | ✅ |
Tier 2 Support §
- The Standard Library supports this target, but it is possible that some APIs will give an "Unsupported OS" compile error. One can link with libc or other libraries to fill in the gaps in the standard library. The 📖 icon means the standard library is too incomplete to be considered Tier 2 worthy.
- These targets are known to work, but may not be automatically tested, so there are occasional regressions. 🔍 means that nobody has really looked into this target so whether or not it works is unknown.
- Some tests may be disabled for these targets as we work toward Tier 1 Support.
| free standing | Linux 3.16+ | macOS 11+ | Windows 10+ | FreeBSD 12.0+ | NetBSD 8.0+ | Dragon FlyBSD 5.8+ | OpenBSD 7.3+ | UEFI | |
|---|---|---|---|---|---|---|---|---|---|
| x86_64 | Tier 1 | Tier 1 | Tier 1 | Tier 1 | ✅ | ✅ | ✅ | ✅ | ✅ |
| x86 | Tier 1 | ✅ | 💀 | ✅ | 🔍 | 🔍 | N/A | 🔍 | ✅ |
| aarch64 | Tier 1 | ✅ | Tier 1 | ✅ | 🔍 | 🔍 | N/A | 🔍 | 🔍 |
| arm | Tier 1 | ✅ | 💀 | 🔍 | 🔍 | 🔍 | N/A | 🔍 | 🔍 |
| mips64 | ✅ | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | 🔍 | N/A |
| mips | Tier 1 | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | 🔍 | N/A |
| powerpc64 | Tier 1 | ✅ | 💀 | N/A | 🔍 | 🔍 | N/A | 🔍 | N/A |
| powerpc | Tier 1 | ✅ | 💀 | N/A | 🔍 | 🔍 | N/A | 🔍 | N/A |
| riscv64 | Tier 1 | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | 🔍 | 🔍 |
| sparc64 | Tier 1 | ✅ | N/A | N/A | 🔍 | 🔍 | N/A | 🔍 | N/A |
Tier 3 Support §
- The standard library has little to no knowledge of the existence of this target.
- If this target is provided by LLVM, LLVM has the target enabled by default.
- These targets are not frequently tested; one will likely need to contribute to Zig in order to build for these targets.
- The Zig compiler might need to be updated with a few things such as
- what sizes are the C integer types
- C ABI calling convention for this target
- start code and default panic handler
zig targetsis guaranteed to include this target.
| freestanding | Linux 3.16+ | Windows 10+ | FreeBSD 12.0+ | NetBSD 8.0+ | UEFI | |
|---|---|---|---|---|---|---|
| x86_64 | Tier 1 | Tier 1 | Tier 1 | Tier 2 | Tier 2 | Tier 2 |
| x86 | Tier 1 | Tier 2 | Tier 2 | ✅ | ✅ | Tier 2 |
| aarch64 | Tier 1 | Tier 2 | Tier 2 | ✅ | ✅ | ✅ |
| arm | Tier 1 | Tier 2 | ✅ | ✅ | ✅ | ✅ |
| mips64 | Tier 2 | Tier 2 | N/A | ✅ | ✅ | N/A |
| mips | Tier 1 | Tier 2 | N/A | ✅ | ✅ | N/A |
| riscv64 | Tier 1 | Tier 2 | N/A | ✅ | ✅ | ✅ |
| powerpc32 | Tier 2 | Tier 2 | N/A | ✅ | ✅ | N/A |
| powerpc64 | Tier 2 | Tier 2 | N/A | ✅ | ✅ | N/A |
| bpf | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| hexagon | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| amdgcn | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| sparc | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| s390x | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| lanai | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| csky | ✅ | ✅ | N/A | ✅ | ✅ | N/A |
| freestanding | emscripten | |
|---|---|---|
| wasm32 | Tier 1 | ✅ |
Tier 4 Support §
- Support for these targets is entirely experimental.
- If this target is provided by LLVM, LLVM may have the target as an
experimental target, which means that you need to use Zig-provided binaries
for the target to be available, or build LLVM from source with special configure flags.
zig targetswill display the target if it is available. - This target may be considered deprecated by an official party, in which case this target will remain forever stuck in Tier 4.
- This target may only support
-femit-asmand cannot emit object files, in which case-fno-emit-binis enabled by default and cannot be overridden.
Tier 4 targets:
- avr
- riscv32
- xcore
- nvptx
- msp430
- r600
- arc
- tce
- le
- amdil
- hsail
- spir
- kalimba
- shave
- renderscript
- 32-bit x86 macOS, 32-bit ARM macOS, powerpc32 and powerpc64 macOS, because Apple has officially dropped support for them.
Redesign How Autodoc Works §

This release deletes the previous (experimental) Autodoc implementation and replaces it with a new (not experimental!) one.
The old implementation looked like this:
5987 src/Autodoc.zig 435 src/autodoc/render_source.zig 10270 lib/docs/commonmark.js 1245 lib/docs/index.html 5242 lib/docs/main.js 2146 lib/docs/ziglexer.js 25325 total
After compilation (sizes are for standard library documentation):
272K commonmark.js 3.8M data-astNodes.js 360K data-calls.js 767K data-comptimeExprs.js 2.2M data-decls.js 896K data-exprs.js 13K data-files.js 45 data-guideSections.js 129 data-modules.js 15 data-rootMod.js 294 data-typeKinds.js 3.2M data-types.js 38K index.html 158K main.js 36M src/ (470 .zig.html files) 78K ziglexer.js
Total output size: 47M (5.7M gzipped)
src/Autodoc.zig processed ZIR code, outputting JSON data for a web application to consume. This resulted in a lot of code ineffectively trying to reconstruct the AST from no-longer-available data.
lib/docs/commonmark.js was a third-party markdown implementation that supported too many features; for example I do not want it to be possible to have HTML tags in doc comments, because that would make source code uglier. Only markdown that looks good both as source and rendered should be allowed.
lib/docs/ziglexer.js was an implementation of Zig language tokenization in JavaScript, despite Zig already exposing its own tokenizer in the standard library. When I saw this added to the zig project, a little part of me died inside.
src/autodoc/render_source.zig was a tool that converted .zig files to a syntax-highlighted but non-interactive .zig.html files.
The new implementation looks like this:
942 lib/docs/main.js 403 lib/docs/index.html 933 lib/docs/wasm/markdown.zig 226 lib/docs/wasm/Decl.zig 1500 lib/docs/wasm/markdown/Parser.zig 254 lib/docs/wasm/markdown/renderer.zig 192 lib/docs/wasm/markdown/Document.zig 941 lib/docs/wasm/main.zig 1038 lib/docs/wasm/Walk.zig 6630 total
After compilation (sizes are for standard library documentation):
12K index.html 32K main.js 192K main.wasm 12M sources.tar
Total output size: 12M (2.3M gzipped)
As you can see, it is both dramatically simpler in terms of implementation as well as build artifacts. Now there are exactly 4 files instead of many, with a 4x reduction in total file size of the generated web app.
However, not only is it simpler, it is actually more powerful than the old system, because instead of processing ZIR, this system processes the source files directly, meaning it has 100% of the information and never needs to piece anything together backwards.
This strategy uses a WebAssembly module written in Zig. This allows it to reuse components from the compiler, such as the tokenizer, parser, and other utilities for operating on Zig code.
The sources.tar file, after being decompressed by the HTTP layer, is fed directly into the wasm module's memory. The tar file is parsed using std.tar and source files are parsed in place, with some additional computations added to hash tables on the side.
There is room for introducing worker threads to speed up the parsing, although single-threaded it is already so fast that it does not seem necessary.
Installed Standard Library Documentation §
In Zig 0.11.0, a Zig installation comes with a docs/std/
directory that contains those 47M of output artifacts mentioned above.
This rewrite removed those artifacts from Zig installations, instead
offering the zig std command, which hosts std lib autodocs and
spawns a browser window to view them. When this command is activated,
lib/compiler/std-docs.zig is compiled from source to perform
this operation.
The HTTP server creates the requested files on the fly, including
rebuilding main.wasm if any of its source files changed, and constructing
sources.tar, meaning that any source changes to the documented files,
or to the autodoc system itself are immediately reflected when
viewing docs. Prefixing the URL with /debug results in a debug
build of the WebAssembly module.
This means contributors can test changes to Zig standard library documentation, as well as autodocs functionality, by pressing refresh in their browser window, using a only binary distribution of Zig.
In total, this reduced the Zig installation size from 317M to 268M (-15%).
A ReleaseSmall build of the compiler shrinks from 10M to 9.8M (-1%).
Time to Generate Documentation §
Autodocs generation is now done properly as part of the pipeline of the compiler rather than tacked on at the end. It also no longer has any dependencies on other parts of the pipeline.
This is how long it now takes to generate standard library documentation:
Benchmark 1 (3 runs): old/zig test /home/andy/dev/zig/lib/std/std.zig -fno-emit-bin -femit-docs=docs measurement mean ± σ min … max outliers delta wall_time 13.3s ± 405ms 12.8s … 13.6s 0 ( 0%) 0% peak_rss 1.08GB ± 463KB 1.08GB … 1.08GB 0 ( 0%) 0% cpu_cycles 54.8G ± 878M 54.3G … 55.8G 0 ( 0%) 0% instructions 106G ± 313K 106G … 106G 0 ( 0%) 0% cache_references 2.11G ± 35.4M 2.07G … 2.14G 0 ( 0%) 0% cache_misses 41.3M ± 455K 40.8M … 41.7M 0 ( 0%) 0% branch_misses 116M ± 67.8K 116M … 116M 0 ( 0%) 0% Benchmark 2 (197 runs): new/zig build-obj -fno-emit-bin -femit-docs=docs ../lib/std/std.zig measurement mean ± σ min … max outliers delta wall_time 24.6ms ± 1.03ms 22.8ms … 28.3ms 4 ( 2%) ⚡- 99.8% ± 0.3% peak_rss 87.3MB ± 60.6KB 87.2MB … 87.4MB 0 ( 0%) ⚡- 91.9% ± 0.0% cpu_cycles 38.4M ± 903K 37.4M … 46.1M 13 ( 7%) ⚡- 99.9% ± 0.2% instructions 39.7M ± 12.4K 39.7M … 39.8M 0 ( 0%) ⚡-100.0% ± 0.0% cache_references 2.65M ± 89.1K 2.54M … 3.43M 3 ( 2%) ⚡- 99.9% ± 0.2% cache_misses 197K ± 5.71K 186K … 209K 0 ( 0%) ⚡- 99.5% ± 0.1% branch_misses 184K ± 1.97K 178K … 190K 6 ( 3%) ⚡- 99.8% ± 0.0%
It used to take upwards of 13 seconds. Now it takes 25ms.
New Autodoc Features §
Reliable Linkification §
This stems from the fact that with full source files we have all the information, and can write more robust code to look up identifiers from the context they occur in.
Interactive Source Listings §
Press u to go to source code for any declaration:
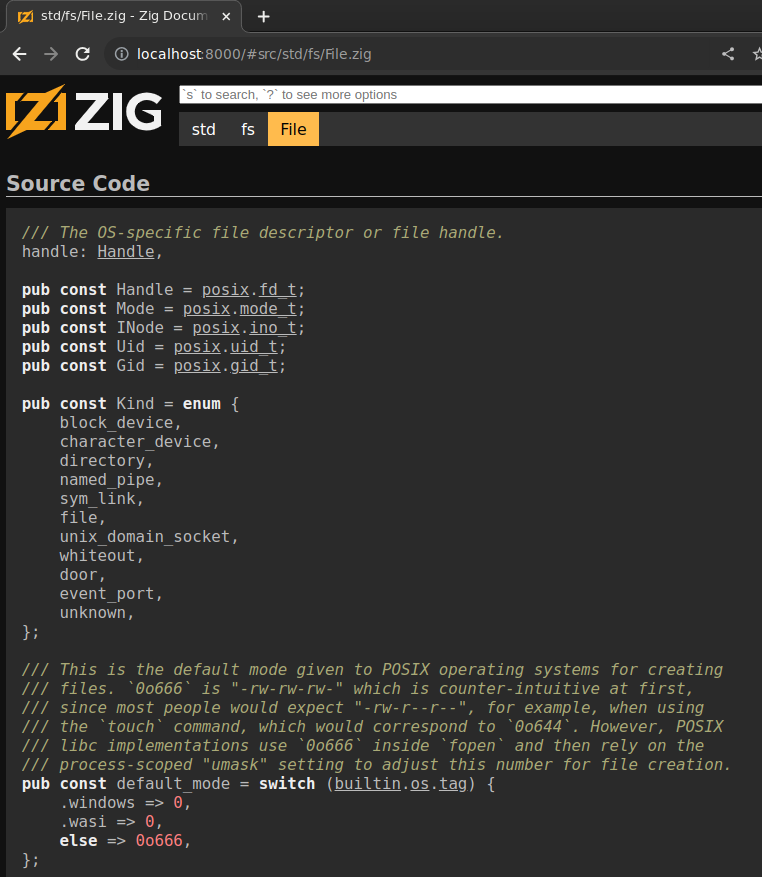
The links take you to the API page for that specific link by changing the location hash.
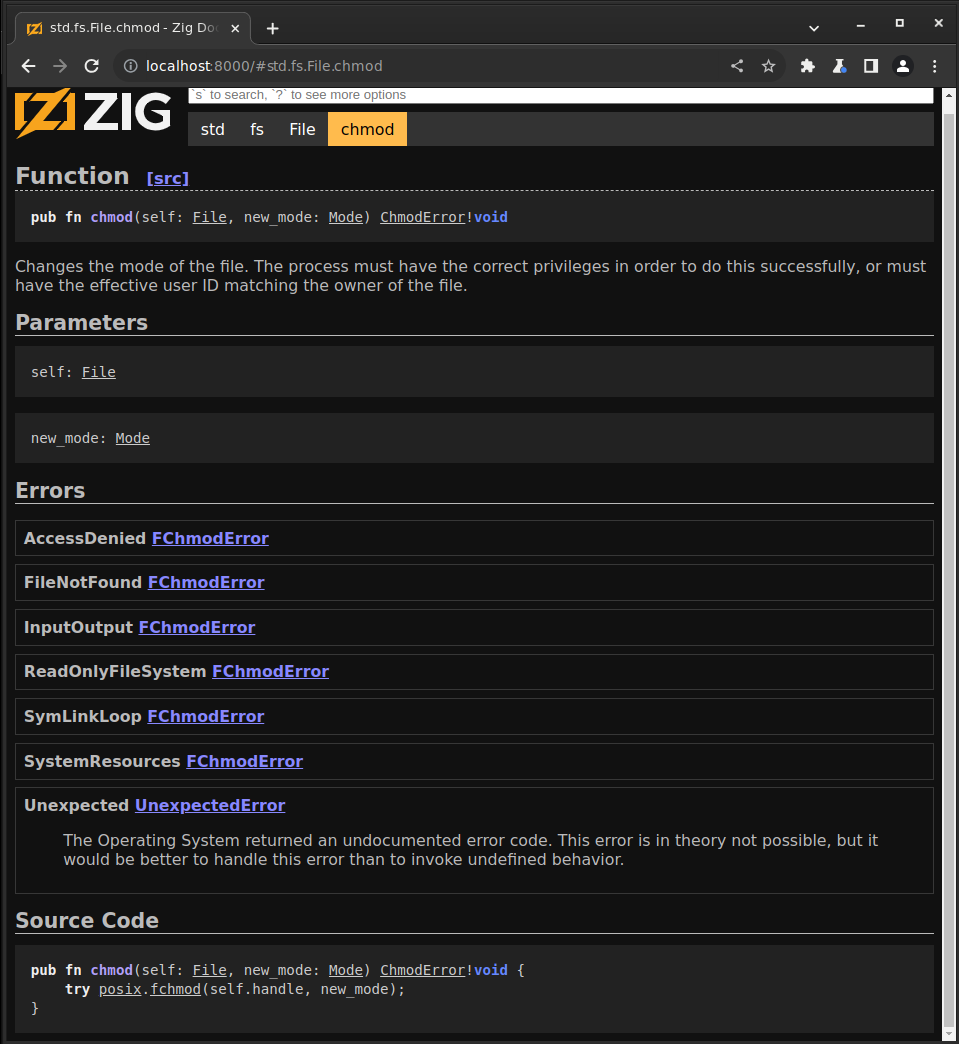
Embedded Source Listings §
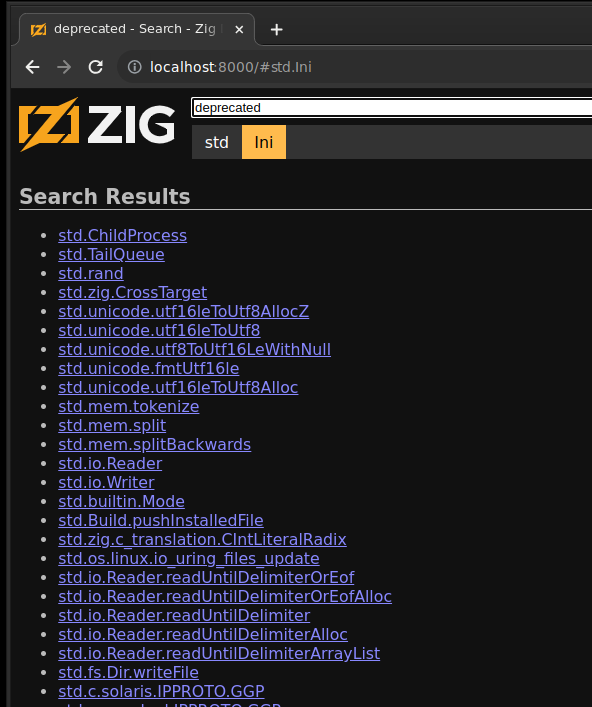
Search Includes Doc Comments §
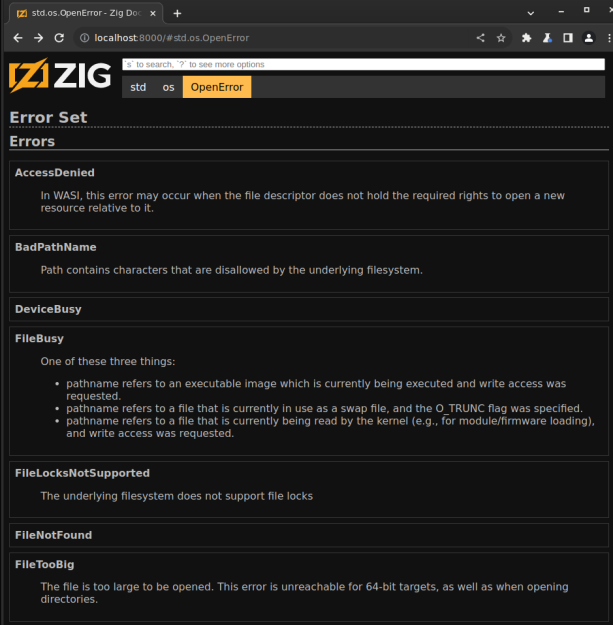
Error Set View §
Merged error sets are detected:
Errors that come from other declarations are linked:
Errors are also shown on function view:
Correct Type Detection §

Previous implementation guesses wrong on the type of options as well as DynLib.
Correct Implementation of Scroll History §
The previous implementation implemented scroll history in JavaScript, which is impossible to do correctly. The new system makes careful use of the 'popstate' event combined with the history API to scroll to the top of the window only when the user navigates to a new link - respecting the browser's saved scroll history in all other cases.
For more details see the commit diff.
Language Changes §
Unnecessary Use of var §
Zig 0.12.0 introduces a new compile error which is emitted when a local variable is declared as
a var, but the compiler can infer that const would suffice.
const expectEqual = @import("std").testing.expectEqual;
test "unnecessary use of var" {
var x: u32 = 123;
try expectEqual(123, x);
}$ zig test unnecessary_var.zig docgen_tmp/unnecessary_var.zig:3:9: error: local variable is never mutated var x: u32 = 123; ^ docgen_tmp/unnecessary_var.zig:3:9: note: consider using 'const'
As indicated by the error message, the solution is simple: use const instead
where applicable.
Result Location Semantics §
Zig 0.12.0 contains several enhancements to Result Location Semantics (RLS).
This release implements forwarding of result types through the address-of operator (&). This allows
syntactic constructs which rely on result types, such as anonymous initializations .{ ... }
and casting builtins like @intCast, to function correctly in the presence of the
address-of operator:
const S = struct { x: u32 };
const int: u64 = 123;
const val: *const S = &.{ .x = @intCast(int) };
comptime {
_ = val;
}$ zig test address_of_rls.zig All 0 tests passed.
In addition, Zig 0.12.0 removes the ability for result locations to propagate through @as
and explicitly-typed aggregate initializations T{ ... }. This restriction is in place to
simplify the language design: previous releases contained several bugs relating to incorrect casting of result pointers.
Aggregate Destructuring §
Zig 0.12.0 introduces a new syntax to allow destructuring indexable aggregates: that is, tuples, vectors, and arrays. Writing a sequence of lvalues or local variable declarations on the left-hand side of the assignment will attempt to destructure the value specified on the right-hand side:
const std = @import("std");
const assert = std.debug.assert;
const expectEqual = std.testing.expectEqual;
test "destructure array" {
var z: u32 = undefined;
const x, var y, z = [3]u32{ 1, 2, 3 };
y += 10;
try expectEqual(1, x);
try expectEqual(12, y);
try expectEqual(3, z);
}
test "destructure vector" {
// Comptime-known values are propagated as you would expect.
const x, const y = @Vector(2, u32){ 1, 2 };
comptime assert(x == 1);
comptime assert(y == 2);
}
test "destructure tuple" {
var runtime: u32 = undefined;
runtime = 123;
const x, const y = .{ 42, runtime };
// The first tuple field is a `comptime` field, so `x` is comptime-known even
// though `y` is runtime-known.
comptime assert(x == 42);
try expectEqual(123, y);
}$ zig test destructure.zig 1/3 destructure.test.destructure array... OK 2/3 destructure.test.destructure vector... OK 3/3 destructure.test.destructure tuple... OK All 3 tests passed.
Slices cannot be directly destructured. To destructure values from a slice, convert it to an array by slicing
with comptime-known bounds, such as slice[0..3].*.
Namespace Type Equivalence §
In Zig, struct, enum, union, and opaque types are special. They
do not use structural equivalence, like tuples and arrays do; instead, they create distinct types. These types have
namespaces, and thus may contain declarations. For this reason, they can be referred to collectively as "namespace
types".
In 0.11.0, every time a declaration of such a type was semantically analyzed, a new type was created. Equivalence of
generic types was handled via memoization of comptime function calls; i.e.
std.ArrayList(u8) == std.ArrayList(u8) held because the ArrayList function was only called
once, and its results memoized.
In 0.12.0, this has changed. Namespace types are now deduplicated based on two factors: their source location, and their captures.
The "captures" of a type refers to the set of comptime-known types and values which it closes over. In other words,
it is the set of values referenced within the type but declared outside of it. For instance, the
comptime T: type parameter of std.ArrayList is captured by the type it returns. If two
namespace types are declared by the same piece of code and have the same captures, they are now considered to be
precisely the same type.
Note that the compiler will still memoize comptime calls: that hasn't changed. However, this memoization no longer has a meaningful impact on language semantics.
It is unlikely that this change will cause breakage in existing code. The most likely scenario where it could is something like the following:
fn MakeOpaque(comptime n: comptime_int) type {
_ = n;
return opaque {};
}
const A = MakeOpaque(0);
const B = MakeOpaque(1);In Zig 0.11.0, this code would create two distinct types, because the calls to MakeOpaque are distinct
and thus the opaque declaration was analyzed separately for each call. In Zig 0.12.0, these types are
identical (A == B), because while the function is called twice, the declaration does not capture any
value.
This code can be fixed by forcing the type declaration to capture n:
fn MakeOpaque(comptime n: comptime_int) type {
return opaque {
comptime {
_ = n;
}
};
}
const A = MakeOpaque(0);
const B = MakeOpaque(1);Since n is referenced within the opaque declaration, this code creates two distinct types.
Comptime Memory Changes §
Zig 0.12.0 overhauls the compiler's internal representation of comptime memory, and more specifically
comptime-mutable memory (i.e. comptime var). This overhaul comes with some user-facing
changes in the form of new restrictions on what you can do with a comptime var.
The first, and most significant, new rule is that a pointer to a comptime var is never
allowed to become runtime-known. For instance, consider the following snippet:
test "runtime-known comptime var pointer" {
comptime var x: u32 = 123;
// `var` makes `ptr` runtime-known
var ptr: *const u32 = undefined;
ptr = &x;
if (ptr.* != 123) return error.TestFailed;
}$ zig test comptime_var_ptr_runtime.zig docgen_tmp/comptime_var_ptr_runtime.zig:5:11: error: runtime value contains reference to comptime var ptr = &x; ^~ docgen_tmp/comptime_var_ptr_runtime.zig:5:11: note: comptime var pointers are not available at runtime
In previous versions of Zig, this test passed as you might expect. In Zig 0.12.0, it emits a compile error,
because the assignment to ptr makes the value &x - which is a pointer to a
comptime var - runtime-known.
Such pointers can also become runtime-known by, for instance, being passed to a function called at runtime:
test "comptime var pointer as runtime argument" {
comptime var x: u32 = 123;
if (load(&x) != 123) return error.TestFailed;
}
fn load(ptr: *const u32) u32 {
return ptr.*;
}$ zig test comptime_var_ptr_runtime_arg.zig docgen_tmp/comptime_var_ptr_runtime_arg.zig:3:14: error: runtime value contains reference to comptime var if (load(&x) != 123) return error.TestFailed; ^~ docgen_tmp/comptime_var_ptr_runtime_arg.zig:3:14: note: comptime var pointers are not available at runtime
This test also emits a compile error in Zig 0.12.0. The call to load occurs at runtime, and its
ptr parameter is not marked comptime, so ptr is runtime-known
within the body of load. This means the call to load makes the pointer &x
runtime-known, hence the compile error.
This restriction was put in place to fix some soundness bugs. When a pointer to a comptime var
becomes runtime-known, mutations to it become invalid since the pointed-to data becomes constant, but the type system
fails to reflect this, leading to the potential for runtime segmentation faults in what appears to be valid code. In
addition, the value you read from such a pointer at runtime would be its "final" comptime value, which was an
unintuitive behavior. Thus, these pointers can no longer be runtime-known.
The second new restriction is that a pointer to a comptime var is never allowed to be contained
within the resolved value of a global declaration. For instance, consider the following snippet:
const ptr: *const u32 = ptr: {
var x: u32 = 123;
break :ptr &x;
};
comptime {
_ = ptr;
}$ zig test comptime_var_ptr_global.zig docgen_tmp/comptime_var_ptr_global.zig:1:30: error: global variable contains reference to comptime var const ptr: *const u32 = ptr: { ~~~~~^ referenced by: comptime_0: docgen_tmp/comptime_var_ptr_global.zig:6:9 remaining reference traces hidden; use '-freference-trace' to see all reference traces
Here, ptr is a global declaration whose value is a pointer to a comptime var.
This declaration was permitted in Zig 0.11.0, but raises a compile error in Zig 0.12.0. The same rule applies in
more complex cases, such as when the pointer is contained within a struct field:
const S = struct { ptr: *const u32 };
const val: S = blk: {
var x: u32 = 123;
break :blk .{ .ptr = &x };
};
comptime {
_ = val;
}$ zig test comptime_var_ptr_global_struct.zig docgen_tmp/comptime_var_ptr_global_struct.zig:2:21: error: global variable contains reference to comptime var const val: S = blk: { ~~~~~^ referenced by: comptime_0: docgen_tmp/comptime_var_ptr_global_struct.zig:7:9 remaining reference traces hidden; use '-freference-trace' to see all reference traces
This code raises the same compile error as the previous example. This restriction has been put in place primarily to aid the implementation of incremental compilation in the Zig compiler, which depends on the fact that analysis of global declarations is order-independent, and the dependencies between declarations can be easily modeled.
The most common way for this to manifest as a compile error in existing code is if a function constructs a slice at comptime which is then used at runtime. For instance, consider the following snippet:
fn getName() []const u8 {
comptime var buf: [9]u8 = undefined;
// In practice there would likely be more complex logic here to populate `buf`.
@memcpy(&buf, "some name");
return &buf;
}
test getName {
try @import("std").testing.expectEqualStrings("some name", getName());
}$ zig test construct_slice_comptime.zig docgen_tmp/construct_slice_comptime.zig:5:12: error: runtime value contains reference to comptime var return &buf; ^~~~ docgen_tmp/construct_slice_comptime.zig:5:12: note: comptime var pointers are not available at runtime referenced by: decltest.getName: docgen_tmp/construct_slice_comptime.zig:8:64 remaining reference traces hidden; use '-freference-trace' to see all reference traces
A call to getName returns a slice whose ptr field is a pointer to a
comptime var. This means the value cannot be used at runtime, nor can it appear in the value
of a global declaration. This code can be fixed by promoting the computed data to a const
after filling the buffer:
fn getName() []const u8 {
comptime var buf: [9]u8 = undefined;
// In practice there would likely be more complex logic here to populate `buf`.
@memcpy(&buf, "some name");
const final_name = buf;
return &final_name;
}
test getName {
try @import("std").testing.expectEqualStrings("some name", getName());
}$ zig test construct_slice_comptime.zig 1/1 construct_slice_comptime.decltest.getName... OK All 1 tests passed.
Like in previous versions of Zig, comptime-known consts have infinite lifetime, and the
restrictions discussed here do not apply to them. Therefore, this code functions as expected.
Another possible failure mode is in code which used the old semantics to create global mutable comptime state. For instance, the following snippet attempts to create a global comptime counter:
const counter: *u32 = counter: {
var n: u32 = 0;
break :counter &n;
};
comptime {
counter.* += 1;
}$ zig test global_comptime_counter.zig docgen_tmp/global_comptime_counter.zig:1:32: error: global variable contains reference to comptime var const counter: *u32 = counter: { ~~~~~~~~~^ referenced by: comptime_0: docgen_tmp/global_comptime_counter.zig:6:5 remaining reference traces hidden; use '-freference-trace' to see all reference traces
This code emits a compile error in Zig 0.12.0. This use case is not and will not be supported by Zig: any mutable comptime state must be represented locally.
@fieldParentPtr §
The first argument is removed in favor of using the result type.
Migration guide:
const parent_ptr = @fieldParentPtr(Parent, "field_name", field_ptr);const parent_ptr: *Parent = @fieldParentPtr("field_name", field_ptr);or
const parent_ptr: *Parent = @alignCast(@fieldParentPtr("field_name", field_ptr));depending on what parent pointer alignment the compiler is able to prove.
The second form is more portable, since it's possible for the
@alignCast to be needed for some targets but not others.
Disallow alignment on function type §
Zig 0.11.0 allowed function types to specify an alignment. This is disallowed in Zig 0.12.0, because is it a property of function declarations and pointers, not of function types.
comptime {
_ = fn () align(4) void;
}$ zig test func_type_align.zig docgen_tmp/func_type_align.zig:2:21: error: function type cannot have an alignment _ = fn () align(4) void; ^
@errorCast §
Previous releases of Zig included an @errSetCast builtin which performed a safety-checked
cast from one error set to another, potentially smaller, one. In Zig 0.12.0, this builtin is replaced with
@errorCast. Previous uses will continue to work, but in addition, this new builtin can cast
the error set of an error union:
const testing = @import("std").testing;
test "@errorCast error set" {
const err: error{Foo, Bar} = error.Foo;
const casted: error{Foo} = @errorCast(err);
try testing.expectEqual(error.Foo, casted);
}
test "@errorCast error union" {
const err: error{Foo, Bar}!u32 = error.Foo;
const casted: error{Foo}!u32 = @errorCast(err);
try testing.expectError(error.Foo, casted);
}
test "@errorCast error union payload" {
const err: error{Foo, Bar}!u32 = 123;
const casted: error{Foo}!u32 = @errorCast(err);
try testing.expectEqual(123, casted);
}$ zig test error_cast.zig 1/3 error_cast.test.@errorCast error set... OK 2/3 error_cast.test.@errorCast error union... OK 3/3 error_cast.test.@errorCast error union payload... OK All 3 tests passed.
@abs §
Previous releases of Zig included the @fabs builtin. This has been replaced with a new
@abs builtin, which is able to operate on integers as well as floats:
const expectEqual = @import("std").testing.expectEqual;
test "@abs on float" {
const x: f32 = -123.5;
const y = @abs(x);
try expectEqual(123.5, y);
}
test "@abs on int" {
const x: i32 = -12345;
const y = @abs(x);
try expectEqual(12345, y);
}$ zig test abs.zig 1/2 abs.test.@abs on float... OK 2/2 abs.test.@abs on int... OK All 2 tests passed.
Standard Library §
Windows Command Line Argument Parsing §
On Windows, the command line arguments of a program are a single WTF-16 encoded string and it's up to the program to split it into an array of strings. In C/C++, the entry point of the C runtime takes care of splitting the command line and passing argc/argv to the main function.
Previously, std.process.argsAlloc and related functions did not fully match the parsing behavior of
the C runtime and would split the command line incorrectly in some cases. For example, when encountering consecutive
double quotes inside a quoted block like "foo""bar", these functions would produce foobar
instead of the expected foo"bar
This release updates Zig's command line splitting to match the post-2008 splitting behavior of the C runtime, which ensures consistent behavior between Zig and modern C/C++ programs on Windows. Additionally, the suggested mitigation for BatBadBut relies on the post-2008 C runtime splitting behavior for roundtripping of the arguments given to cmd.exe.
The BadBatBut mitigation did not make the 0.12.0 release cutoff.
Bring-Your-Own-OS API Layer Regressed §
Previous versions of Zig allowed applications to override the POSIX API layer of the standard library. This release intentionally removes this ability, with no migration path offered.
This was a mistake from day one. This is the wrong abstraction layer to do this in.
The alternate plan for this is to make all I/O operations require an IO interface parameter, similar to how allocations require an Allocator interface parameter today.
Such a plan is not yet implemented, so applications which require this functionality must maintain a fork of the standard library until then.
std.os renamed to std.posix §
Migration guide:
std.os.abort();std.posix.abort();Generally, one should prefer to use the higher-level cross-platform abstractions rather than reaching
into the POSIX API layer. For example, std.process.exit is more portable than
std.posix.exit. You should generally expect the API inside std.posix
to be available on a given OS when the OS implements that corresponding POSIX functionality.
Ryu Floating-Point Formatting §
Zig 0.12.0 replaces the previous errol floating point formatting algorithm with one based on Ryu, a modern algorithm for converting IEEE-754 floating-point numbers to decimal strings.
The improvements this brings are:
- Ability to format f80 and f128 types
- More accurate f16 and f32 formatting
- Complete round-trip support for every float type
- Generic backend that can be used to print any float of a general number of bits (less than or equal to 128 bits)
Behavior Differences:
- Exponents are no longer padded with a leading 0 to 2-digits and if positive, the sign is no longer printed:
errol: 1e+02 ryu: 1e2
- Fractional values of 0 are omitted in full precision mode:
errol: 2.0e+00 ryu: 2e0
- Full precision output is more accurate in all cases other than f64,
since we no longer do a cast internally to f64:
# Ryu 3.1234567891011121314151617181920212E0 :f128 3.1234567891011121314E0 :f80 3.1234567891011121314E0 :c_longdouble 3.123456789101112E0 :f64 3.1234567E0 :f32 3.123E0 :f16 ## Errol 3.123456789101112e+00 :f128 3.123456789101112e+00 :f80 3.123456789101112e+00 :c_longdouble 3.123456789101112e+00 :f64 3.12345671e+00 :f32 3.123046875e+00 :f16
- Additionally, rounding behaviour in these cases can differ in the fixed
precision case as the shortest representation will typically differ:
# bits: 141333 # precision: 3 # std_shortest: 1.98049715e-40 # ryu_shortest: 1.9805e-40 # type: f32 | | std_dec: 0.000 | ryu_dec: 0.000 | | std_exp: 1.980e-40 | ryu_exp: 1.981e-40
Performance: ~2.3x performance improvement
Code Size: roughly +5KB (2x)
Reworked HTTP §
First, some pretty straightforward changes:
- don't emit Server HTTP header. Let the user add that if they wish to. It's not strictly necessary, and arguably a harmful default.
- correct the error set of
finishto not have NotWriteable and MessageTooLong in it - protect against zero-length chunks in Server
- add missing redirect behavior option to FetchOptions and make it an enum instead of 2 fields
error.CompressionNotSupportedis renamed toerror.CompressionUnsupported, matching the naming convention from all the other errors in the same set.- Removed documentation comments that were redundant with field and type names.
- Disabling zstd decompression in the server for now; see #18937.
- Automatically handle expect: 100-continue requests
Next, removed the ability to heap-allocate the buffer for headers. The buffer for HTTP headers is now always provided via a static buffer. As a consequence, OutOfMemory is no longer a member of the read() error set, and the API and implementation of Client and Server are simplified. error.HttpHeadersExceededSizeLimit is renamed to error.HttpHeadersOversize.
Finally, the big changes:
Removal of std.http.Headers §
Instead, some headers are provided via explicit field names populated while parsing the HTTP request/response, and some are provided via new fields that support passing extra, arbitrary headers. This resulted in simplification of logic in many places, as well as elimination of the possibility of failure in many places. There is less deinitialization code happening now. Furthermore, it made it no longer necessary to clone the headers data structure in order to handle redirects.
http_proxy and https_proxy fields are now pointers since it is common for them to be unpopulated.
loadDefaultProxies is changed into initDefaultProxies to communicate that it does not actually load anything from disk or from the network. The function now is leaky; the API user must pass an already instantiated arena allocator. Removes the need to deinitialize proxies.
Before, proxies stored arbitrary sets of headers. Now they only store the authorization value.
Removed the duplicated code between https_proxy and http_proxy. Finally, parsing failures of the environment variables result in errors being emitted rather than silently ignoring the proxy.
Rework Server Entirely §
Mainly, this removes the poorly named wait, send, finish functions, which all operated on the same "Response" object, which was actually being used as the request.
Now, it looks like this:
std.net.Server.accept()gives you astd.net.Server.Connectionstd.http.Server.init()with the connectionServer.receiveHead()gives you a RequestRequest.reader()gives you a body readerRequest.respond()is a one-shot, orRequest.respondStreaming()creates aResponseResponse.writer()gives you a body writerResponse.end()finishes the response;Response.endChunked()allows passing response trailers.
In other words, the type system now guides the API user down the correct path.
receiveHead allows extra bytes to be read into the read buffer, and then will reuse those bytes for the body or the next request upon connection reuse.
respond(), the one-shot function, will send the entire response in one syscall.
Streaming response bodies no longer wastefully wraps every call to write with a chunk header and trailer; instead it only sends the HTTP chunk wrapper when flushing. This means the user can still control when it happens but it also does not add unnecessary chunks.
Empirically, the usage code is significantly less noisy, it has less error handling while handling errors more correctly, it's more obvious what is happening, and it is syscall-optimal.
var read_buffer: [8000]u8 = undefined;
accept: while (true) {
const connection = try http_server.accept();
defer connection.stream.close();
var server = std.http.Server.init(connection, &read_buffer);
while (server.state == .ready) {
var request = server.receiveHead() catch |err| {
std.debug.print("error: {s}\n", .{@errorName(err)});
continue :accept;
};
try static_http_file_server.serve(&request);
}
}pub fn serve(context: *Context, request: *std.http.Server.Request) ServeError!void {
// ...
return request.respond(content, .{
.status = status,
.extra_headers = &.{
.{ .name = "content-type", .value = @tagName(file.mime_type) },
},
});Additionally:
- Uncouple
std.http.HeadParserfrom protocol.zig - Delete
std.Server.Connection; usestd.net.Server.Connectioninstead.- The API user supplies the read buffer when initializing the http.Server, and it is used for the HTTP head as well as a buffer for reading the body into.
- Replace and document the State enum. No longer is there both "start" and "first".
std.http.Client has not yet been reworked in a similar manner as std.http.Server.
deflate reimplemented from first principles §
In Zig 0.11.0, the deflate implementation was ported from the Go standard library, which had a bunch of undesirable properties, such as incorrect use of global variables, comments about Go's optimizer in Zig's codebase, and the requirement of dynamic memory allocation.
Zig 0.12.0 has a new implementation that is not a port of an existing codebase.
The new implementation is roughly 1.2-1.4x faster in decompression and 1.1-1.2x faster in compression. Compressed sizes are pretty much the same in both cases (source).
The new code uses static allocations for all structures, doesn't require allocator. That makes sense especially for deflate where all structures, internal buffers are allocated to the full size. Little less for inflate where the previous verision used less memory by not preallocating to theoretical max size array which are usually not fully used.
For deflate the new implementaiton allocates 395K while previous implementation used 779K. For inflate the new implementation allocates 74.5K while the old one around 36K.
Inflate difference is because we here use 64K history instead of 32K previously.
Migration guide:
const std = @import("std");
// To get this file:
// wget -nc -O war_and_peace.txt https://www.gutenberg.org/ebooks/2600.txt.utf-8
const data = @embedFile("war_and_peace.txt");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer std.debug.assert(gpa.deinit() == .ok);
const allocator = gpa.allocator();
try oldDeflate(allocator);
try new(std.compress.flate, allocator);
try oldZlib(allocator);
try new(std.compress.zlib, allocator);
try oldGzip(allocator);
try new(std.compress.gzip, allocator);
}
pub fn new(comptime pkg: type, allocator: std.mem.Allocator) !void {
var buf = std.ArrayList(u8).init(allocator);
defer buf.deinit();
// Compressor
var cmp = try pkg.compressor(buf.writer(), .{});
_ = try cmp.write(data);
try cmp.finish();
var fbs = std.io.fixedBufferStream(buf.items);
// Decompressor
var dcp = pkg.decompressor(fbs.reader());
const plain = try dcp.reader().readAllAlloc(allocator, std.math.maxInt(usize));
defer allocator.free(plain);
try std.testing.expectEqualSlices(u8, data, plain);
}
pub fn oldDeflate(allocator: std.mem.Allocator) !void {
const deflate = std.compress.v1.deflate;
// Compressor
var buf = std.ArrayList(u8).init(allocator);
defer buf.deinit();
// Remove allocator
// Rename deflate -> flate
var cmp = try deflate.compressor(allocator, buf.writer(), .{});
_ = try cmp.write(data);
try cmp.close(); // Rename to finish
cmp.deinit(); // Remove
// Decompressor
var fbs = std.io.fixedBufferStream(buf.items);
// Remove allocator and last param
// Rename deflate -> flate
// Remove try
var dcp = try deflate.decompressor(allocator, fbs.reader(), null);
defer dcp.deinit(); // Remove
const plain = try dcp.reader().readAllAlloc(allocator, std.math.maxInt(usize));
defer allocator.free(plain);
try std.testing.expectEqualSlices(u8, data, plain);
}
pub fn oldZlib(allocator: std.mem.Allocator) !void {
const zlib = std.compress.v1.zlib;
var buf = std.ArrayList(u8).init(allocator);
defer buf.deinit();
// Compressor
// Rename compressStream => compressor
// Remove allocator
var cmp = try zlib.compressStream(allocator, buf.writer(), .{});
_ = try cmp.write(data);
try cmp.finish();
cmp.deinit(); // Remove
var fbs = std.io.fixedBufferStream(buf.items);
// Decompressor
// decompressStream => decompressor
// Remove allocator
// Remove try
var dcp = try zlib.decompressStream(allocator, fbs.reader());
defer dcp.deinit(); // Remove
const plain = try dcp.reader().readAllAlloc(allocator, std.math.maxInt(usize));
defer allocator.free(plain);
try std.testing.expectEqualSlices(u8, data, plain);
}
pub fn oldGzip(allocator: std.mem.Allocator) !void {
const gzip = std.compress.v1.gzip;
var buf = std.ArrayList(u8).init(allocator);
defer buf.deinit();
// Compressor
// Rename compress => compressor
// Remove allocator
var cmp = try gzip.compress(allocator, buf.writer(), .{});
_ = try cmp.write(data);
try cmp.close(); // Rename to finisho
cmp.deinit(); // Remove
var fbs = std.io.fixedBufferStream(buf.items);
// Decompressor
// Rename decompress => decompressor
// Remove allocator
// Remove try
var dcp = try gzip.decompress(allocator, fbs.reader());
defer dcp.deinit(); // Remove
const plain = try dcp.reader().readAllAlloc(allocator, std.math.maxInt(usize));
defer allocator.free(plain);
try std.testing.expectEqualSlices(u8, data, plain);
}std.posix APIs Gain Type Safety §
For example, let's look at std.posix.termios:
- Add missing API bits to termios and the types of its fields for all 12 operating systems
- Correct API bits on Linux (they were wrong for some CPU architectures)
- Consolidate std.c definitions
- Add type safety to all integers
For example previously this is how you would set immediate mode on a tty:
const in = std.io.getStdIn();
// copy original settings and restore them once done
const original_termios = try std.posix.tcgetattr(in.handle);
defer std.posix.tcsetattr(in.handle, .FLUSH, original_termios) catch {};
// set immediate input mode
var termios = original_termios;
termios.lflag &= ~@as(std.posix.system.tcflag_t, std.posix.system.ICANON);
// flush changes
try std.posix.tcsetattr(in.handle, .FLUSH, termios);Now the middle part looks like this:
// set immediate input mode
var termios = original_termios;
termios.lflag.ICANON = false;This is thanks to the new definitions based on packed struct.
Here's for example the definition of lflag for Linux:
pub const tc_lflag_t = switch (native_arch) {
.powerpc, .powerpcle, .powerpc64, .powerpc64le => packed struct(u32) {
_0: u1 = 0,
ECHOE: bool = false,
ECHOK: bool = false,
ECHO: bool = false,
ECHONL: bool = false,
_5: u2 = 0,
ISIG: bool = false,
ICANON: bool = false,
_9: u1 = 0,
IEXTEN: bool = false,
_11: u11 = 0,
TOSTOP: bool = false,
_23: u8 = 0,
NOFLSH: bool = false,
},
.mips, .mipsel, .mips64, .mips64el => packed struct(u32) {
ISIG: bool = false,
ICANON: bool = false,
_2: u1 = 0,
ECHO: bool = false,
ECHOE: bool = false,
ECHOK: bool = false,
ECHONL: bool = false,
NOFLSH: bool = false,
IEXTEN: bool = false,
_9: u6 = 0,
TOSTOP: bool = false,
_: u16 = 0,
},
else => packed struct(u32) {
ISIG: bool = false,
ICANON: bool = false,
_2: u1 = 0,
ECHO: bool = false,
ECHOE: bool = false,
ECHOK: bool = false,
ECHONL: bool = false,
NOFLSH: bool = false,
TOSTOP: bool = false,
_9: u6 = 0,
IEXTEN: bool = false,
_: u16 = 0,
},
};Many more std.posix APIs were adjusted in a
similar way.
std.builtin Enum Fields Lowercased §
Zig 0.12.0 takes the opportunity to adjust the field names of some enums in std.builtin to align
with our current naming conventions, which dictate that enum fields should be snake_case. The following enums have been updated:
std.builtin.AtomicOrderstd.builtin.ContainerLayoutstd.builtin.Endianstd.builtin.FloatModestd.builtin.GlobalLinkagestd.builtin.LinkMode
Global Configuration §
Previously, when one wanted to override defaults, such as the logging function used by std.log, they would have to define std_options in their root file, like so:
pub const std_options = struct {
pub const logFn = myLogFn;
};Note how std_options above is a struct type definiton. In this release std_options is now an instance of std.Options, making the process of defining overrides less error-prone.
The code above would look like this now:
pub const std_options: std.Options = .{
.logFn = myLogFn,
};And this is the definition of std.Options to see what else you can override.
pub const Options = struct {
enable_segfault_handler: bool = debug.default_enable_segfault_handler,
/// Function used to implement `std.fs.cwd` for WASI.
wasiCwd: fn () os.wasi.fd_t = fs.defaultWasiCwd,
/// The current log level.
log_level: log.Level = log.default_level,
log_scope_levels: []const log.ScopeLevel = &.{},
logFn: fn (
comptime message_level: log.Level,
comptime scope: @TypeOf(.enum_literal),
comptime format: []const u8,
args: anytype,
) void = log.defaultLog,
fmt_max_depth: usize = fmt.default_max_depth,
cryptoRandomSeed: fn (buffer: []u8) void = @import("crypto/tlcsprng.zig").defaultRandomSeed,
crypto_always_getrandom: bool = false,
crypto_fork_safety: bool = true,
/// By default Zig disables SIGPIPE by setting a "no-op" handler for it. Set this option
/// to `true` to prevent that.
///
/// Note that we use a "no-op" handler instead of SIG_IGN because it will not be inherited by
/// any child process.
///
/// SIGPIPE is triggered when a process attempts to write to a broken pipe. By default, SIGPIPE
/// will terminate the process instead of exiting. It doesn't trigger the panic handler so in many
/// cases it's unclear why the process was terminated. By capturing SIGPIPE instead, functions that
/// write to broken pipes will return the EPIPE error (error.BrokenPipe) and the program can handle
/// it like any other error.
keep_sigpipe: bool = false,
/// By default, std.http.Client will support HTTPS connections. Set this option to `true` to
/// disable TLS support.
///
/// This will likely reduce the size of the binary, but it will also make it impossible to
/// make a HTTPS connection.
http_disable_tls: bool = false,
side_channels_mitigations: crypto.SideChannelsMitigations = crypto.default_side_channels_mitigations,
};Pointer Stability Locks §
This adds std.debug.SafetyLock and uses it in standard library hash maps by adding lockPointers() and unlockPointers().
This provides a way to detect when an illegal modification has happened and panic rather than invoke undefined behavior:
const std = @import("std");
pub fn main() !void {
const gpa = std.heap.page_allocator;
var map: std.AutoHashMapUnmanaged(i32, i32) = .{};
const gop = try map.getOrPut(gpa, 1234);
map.lockPointers();
defer map.unlockPointers();
gop.value_ptr.* = try calculate(gpa, &map);
}
fn calculate(gpa: std.mem.Allocator, m: anytype) !i32 {
try m.put(gpa, 42, 420);
return 999;
}$ zig build-exe safety_locks.zig $ ./safety_locks thread 223429 panic: reached unreachable code /home/andy/local/lib/zig/std/debug.zig:403:14: 0x1036b4d in assert (safety_locks) if (!ok) unreachable; // assertion failure ^ /home/andy/local/lib/zig/std/debug.zig:2845:15: 0x10375fb in lock (safety_locks) assert(l.state == .unlocked); ^ /home/andy/local/lib/zig/std/hash_map.zig:1331:44: 0x1066683 in getOrPutContextAdapted__anon_6584 (safety_locks) self.pointer_stability.lock(); ^ /home/andy/local/lib/zig/std/hash_map.zig:1318:56: 0x1037505 in getOrPutContext (safety_locks) const gop = try self.getOrPutContextAdapted(allocator, key, ctx, ctx); ^ /home/andy/local/lib/zig/std/hash_map.zig:1244:52: 0x103765a in putContext (safety_locks) const result = try self.getOrPutContext(allocator, key, ctx); ^ /home/andy/local/lib/zig/std/hash_map.zig:1241:35: 0x1034023 in put (safety_locks) return self.putContext(allocator, key, value, undefined); ^ /home/andy/docgen_tmp/safety_locks.zig:15:14: 0x1033fb6 in calculate__anon_3194 (safety_locks) try m.put(gpa, 42, 420); ^ /home/andy/docgen_tmp/safety_locks.zig:11:36: 0x10341eb in main (safety_locks) gop.value_ptr.* = try calculate(gpa, &map); ^ /home/andy/local/lib/zig/std/start.zig:511:37: 0x1033ec5 in posixCallMainAndExit (safety_locks) const result = root.main() catch |err| { ^ /home/andy/local/lib/zig/std/start.zig:253:5: 0x10339e1 in _start (safety_locks) asm volatile (switch (native_arch) { ^ ???:?:?: 0x0 in ??? (???) (process terminated by signal)
Something nice about this is that if you use the "assume capacity" variants then such mutations are actually well-defined, and don't trigger the problem:
const std = @import("std");
pub fn main() !void {
const gpa = std.heap.page_allocator;
var map: std.AutoHashMapUnmanaged(i32, i32) = .{};
try map.ensureUnusedCapacity(gpa, 2);
const gop = map.getOrPutAssumeCapacity(1234);
map.lockPointers();
defer map.unlockPointers();
gop.value_ptr.* = calculate(&map);
}
fn calculate(m: anytype) i32 {
m.putAssumeCapacity(42, 420);
return 999;
}$ zig build-exe assume_capacity.zig $ ./assume_capacity
Follow-up tasks that did not make the release cutoff:
- introduce pointer stability safety locks to array lists
- introduce pointer stability safety locks to MultiArrayList
- add stack traces to pointer stability safety locks
Build System §
System Package Mode §
Makes the zig build system significantly more friendly to system package maintainers by introducing System Integration Options.
Let's examine this feature using groovebasin as an example project:
Ability to Declare Optional System Library Integration §
--- a/build.zig
+++ b/build.zig
@@ -5,18 +5,8 @@ pub fn build(b: *std.Build) void {
const optimize = b.standardOptimizeOption(.{
.preferred_optimize_mode = .ReleaseSafe,
});
- const libgroove_optimize_mode = b.option(
- std.builtin.OptimizeMode,
- "libgroove-optimize",
- "override optimization mode of libgroove and its dependencies",
- );
const use_llvm = b.option(bool, "use-llvm", "LLVM backend");
- const groove_dep = b.dependency("groove", .{
- .optimize = libgroove_optimize_mode orelse .ReleaseFast,
- .target = target,
- });
-
b.installDirectory(.{
.source_dir = .{ .path = "public" },
.install_dir = .lib,
@@ -31,7 +21,22 @@ pub fn build(b: *std.Build) void {
.use_llvm = use_llvm,
.use_lld = use_llvm,
});
- server.linkLibrary(groove_dep.artifact("groove"));
+
+ if (b.systemIntegrationOption("groove", .{})) {
+ server.linkSystemLibrary("groove");
+ } else {
+ const libgroove_optimize_mode = b.option(
+ std.builtin.OptimizeMode,
+ "libgroove-optimize",
+ "override optimization mode of libgroove and its dependencies",
+ );
+ const groove_dep = b.dependency("groove", .{
+ .optimize = libgroove_optimize_mode orelse .ReleaseFast,
+ .target = target,
+ });
+ server.linkLibrary(groove_dep.artifact("groove"));
+ }
+
b.installArtifact(server);
const run_cmd = b.addRunArtifact(server);With this diff plus some similar changes in the project's dependency tree...
System Integration Help Section §
There is a new --help section:
System Integration Options:
--system [dir] System Package Mode. Disable fetching; prefer system libs
-fsys=[name] Enable a system integration
-fno-sys=[name] Disable a system integration
Available System Integrations: Enabled:
groove no
z no
mp3lame no
vorbis no
ogg no
Using the System Integration Options §
[nix-shell:~/dev/groovebasin]$ zig build -fsys=z
[nix-shell:~/dev/groovebasin]$ ldd zig-out/bin/groovebasin
linux-vdso.so.1 (0x00007fff054c7000)
libz.so.1 => /nix/store/8mw6ssjspf8k1ija88cfldmxlbarl1bb-zlib-1.2.13/lib/libz.so.1 (0x00007fe164675000)
libm.so.6 => /nix/store/whypqfa83z4bsn43n4byvmw80n4mg3r8-glibc-2.37-45/lib/libm.so.6 (0x00007fe164595000)
libc.so.6 => /nix/store/whypqfa83z4bsn43n4byvmw80n4mg3r8-glibc-2.37-45/lib/libc.so.6 (0x00007fe1643ae000)
/nix/store/whypqfa83z4bsn43n4byvmw80n4mg3r8-glibc-2.37-45/lib64/ld-linux-x86-64.so.2 (0x00007fe164696000)
Now, re-run the command but removing -fsys=z:
[nix-shell:~/dev/groovebasin]$ ~/Downloads/zig/build-release/stage4/bin/zig build
[nix-shell:~/dev/groovebasin]$ ldd zig-out/bin/groovebasin
linux-vdso.so.1 (0x00007ffcc23f6000)
libm.so.6 => /nix/store/whypqfa83z4bsn43n4byvmw80n4mg3r8-glibc-2.37-45/lib/libm.so.6 (0x00007f525feea000)
libc.so.6 => /nix/store/whypqfa83z4bsn43n4byvmw80n4mg3r8-glibc-2.37-45/lib/libc.so.6 (0x00007f525fd03000)
/nix/store/whypqfa83z4bsn43n4byvmw80n4mg3r8-glibc-2.37-45/lib64/ld-linux-x86-64.so.2 (0x00007f525ffcc000)
New Release Option §
System package maintainers can provide the new --release option in order to
set a system-wide preference for optimization mode, while respecting the application developer's choice.
--release[=mode] Request release mode, optionally specifying a
preferred optimization mode: fast, safe, small
andy@ark ~/d/a/zlib (main)> zig build --release
the project does not declare a preferred optimization mode. choose: --release=fast, --release=safe, or --release=small
error: the following build command failed with exit code 1:
/home/andy/dev/ayb/zlib/zig-cache/o/6f46a03cb0f5f70d2c891f31086fecc9/build /home/andy/Downloads/zig/build-release/stage3/bin/zig /home/andy/dev/ayb/zlib /home/andy/dev/ayb/zlib/zig-cache /home/andy/.cache/zig --seed 0x3e999c60 --release
andy@ark ~/d/a/zlib (main) [1]> zig build --release=safe
andy@ark ~/d/a/zlib (main)> vim build.zig
andy@ark ~/d/a/zlib (main)> git diff
diff --git a/build.zig b/build.zig
index 76bbb01..1bc13e6 100644
--- a/build.zig
+++ b/build.zig
@@ -5,7 +5,9 @@ pub fn build(b: *std.Build) void {
const lib = b.addStaticLibrary(.{
.name = "z",
.target = b.standardTargetOptions(.{}),
- .optimize = b.standardOptimizeOption(.{}),
+ .optimize = b.standardOptimizeOption(.{
+ .preferred_optimize_mode = .ReleaseFast,
+ }),
});
lib.linkLibC();
lib.addCSourceFiles(.{
andy@ark ~/d/a/zlib (main)> zig build --release
andy@ark ~/d/a/zlib (main)> zig build --release=small
andy@ark ~/d/a/zlib (main)>
This option may be set even if the project's build script does not explicitly expose an optimization configuration option.
Avoid Fetching in System Mode §
--system prevents Zig from fetching packages. Instead, a directory of packages
is provided, populated presumably by the system package manager.
[nix-shell:~/dev/2Pew]$ zig build --system ~/tmp/p -fno-sys=SDL2 error: lazy dependency package not found: /home/andy/tmp/p/1220c5360c9c71c215baa41b46ec18d0711059b48416a2b1cf96c7c2d87b2e8e4cf6 info: remote package fetching disabled due to --system mode info: dependencies might be avoidable depending on build configuration [nix-shell:~/dev/2Pew]$ zig build --system ~/tmp/p [nix-shell:~/dev/2Pew]$ mv ~/.cache/zig/p/1220c5360c9c71c215baa41b46ec18d0711059b48416a2b1cf96c7c2d87b2e8e4cf6 ~/tmp/p [nix-shell:~/dev/2Pew]$ zig build --system ~/tmp/p -fno-sys=SDL2 steps [5/8] zig build-lib SDL2 ReleaseFast native... Compile C Objects [75/128] e_atan2... ^C [nix-shell:~/dev/2Pew]$
Lazy Dependencies §
--- a/build.zig
+++ b/build.zig
- const groove_dep = b.dependency("groove", .{
- .optimize = libgroove_optimize_mode orelse .ReleaseFast,
- .target = target,
- });
+ if (b.lazyDependency("groove", .{
+ .optimize = libgroove_optimize_mode orelse .ReleaseFast,
+ .target = target,
+ })) |groove_dep| {
+ server.linkLibrary(groove_dep.artifact("groove"));
+ }--- a/build.zig.zon
+++ b/build.zig.zon
@@ -5,6 +5,7 @@
.groove = .{
.url = "https://github.com/andrewrk/libgroove/archive/66745eae734e986cd478e7220664f2de902d10a1.tar.gz",
.hash = "1220285f0f6b2be336519a0e612a11617c655f78b0efe1cac12fc73fc1e50c7b3e14",
+ .lazy = true,
},
},
.paths = .{
This makes the dependency only get fetched if it is actually used. The build runner will be rebuilt if any missing lazy dependencies are encountered.
There is an error for using dependency() instead of lazyDependency():
$ zig build -h
thread 2904684 panic: dependency 'groove' is marked as lazy in build.zig.zon which means it must use the lazyDependency function instead
/home/andy/Downloads/zig/lib/std/debug.zig:434:22: 0x11901a9 in panicExtra__anon_18741 (build)
std.builtin.panic(msg, trace, ret_addr);
^
/home/andy/Downloads/zig/lib/std/debug.zig:409:15: 0x1167399 in panic__anon_18199 (build)
panicExtra(null, null, format, args);
^
/home/andy/Downloads/zig/lib/std/Build.zig:1861:32: 0x1136dca in dependency__anon_16705 (build)
std.debug.panic("dependency '{s}{s}' is marked as lazy in build.zig.zon which means it must use the lazyDependency function instead", .{ b.dep_prefix, name });
^
/home/andy/dev/groovebasin/build.zig:33:40: 0x10e8865 in build (build)
const groove_dep = b.dependency("groove", .{
^
/home/andy/Downloads/zig/lib/std/Build.zig:1982:33: 0x10ca783 in runBuild__anon_8952 (build)
.Void => build_zig.build(b),
^
/home/andy/Downloads/zig/lib/build_runner.zig:310:29: 0x10c6708 in main (build)
try builder.runBuild(root);
^
/home/andy/Downloads/zig/lib/std/start.zig:585:37: 0x10af845 in posixCallMainAndExit (build)
const result = root.main() catch |err| {
^
/home/andy/Downloads/zig/lib/std/start.zig:253:5: 0x10af331 in _start (build)
asm volatile (switch (native_arch) {
^
???:?:?: 0x8 in ??? (???)
Unwind information for `???:0x8` was not available, trace may be incomplete
error: the following build command crashed:
/home/andy/dev/groovebasin/zig-cache/o/20af710f8e0e96a0ccc68c47688b2d0d/build /home/andy/Downloads/zig/build-release/stage3/bin/zig /home/andy/dev/groovebasin /home/andy/dev/groovebasin/zig-cache /home/andy/.cache/zig --seed 0x513e8ce9 -Z4472a09906216280 -h
It's allowed to do the reverse - lazyDependency() when the manifest file does not mark it as lazy.
It's probably best practice to always use lazyDependency() in build.zig.
introduce b.path; deprecate LazyPath.relative §
This adds the *std.Build owner to LazyPath so
that lazy paths returned from a dependency can be used in the application's
build script without friction or footguns.
Migration guide:
Source-Relative LazyPath:
.root_source_file = .{ .path = "src/main.zig" },.root_source_file = b.path("src/main.zig"),LazyPath.relative
.root_source_file = LazyPath.relative("src/main.zig"),.root_source_file = b.path("src/main.zig"),Test Runner
.test_runner = "path/to/test_runner.zig",.test_runner = b.path("path/to/test_runner.zig"),Header Installation §
The intent for Compile.installHeader and friends has always been to
bundle the headers alongside an artifact, have them be installed together
with the artifact and get automatically added to the include search paths
of modules that link with the artifact.
In Zig 0.11.0, however, these functions modified the default
install top-level step of the builder, lead to a number of
unexpected results such as installing or not installing the headers
depending on which top-level build steps are invoked.
Zig 0.12.0 changes it so that installed headers are added to the compile
step itself instead of modifying the top-level install step. To handle the
construction of the include search path for dependent linking modules, an
intermediary WriteFile step responsible for constructing the appropriate
include tree is created and set up the first time a module links to an
artifact.
Migration guide:
Compile.installHeader now takes a LazyPath:
for (headers) |h| lib.installHeader(h, h);for (headers) |h| lib.installHeader(b.path(h), h);Compile.installConfigHeader has had its second argument removed and now
uses the value of include_path as its sub path, for parity with
Module.addConfigHeader. Use
artifact.installHeader(config_h.getOutput(), "foo.h")
if you want to set the sub path to something different.
lib.installConfigHeader(avconfig_h, .{});lib.installConfigHeader(avconfig_h);Compile.installHeadersDirectory/installHeadersDirectoryOptions
have been consolidated into Compile.installHeadersDirectory, which takes a
LazyPath and allows exclude/include filters just like InstallDir.
lib.installHeadersDirectoryOptions(.{
.source_dir = upstream.path(""),
.install_dir = .header,
.install_subdir = "",
.include_extensions = &.{
"zconf.h",
"zlib.h",
},
});lib.installHeadersDirectory(upstream.path(""), "", .{
.include_extensions = &.{
"zconf.h",
"zlib.h",
},
});Additionally:
b.addInstallHeaderFilenow takes aLazyPath.- As a workaround for
resurrect emit-h, the generated
-femit-hheader is no longer emitted even when the user specifies an override forh_dir. If you absolutely need the emitted header, you now need to doinstall_artifact.emitted_h = artifact.getEmittedH()until-femit-his fixed. - Added
WriteFile.addCopyDirectory, which functions very similar to InstallDir. InstallArtifacthas been updated to install the bundled headers alongide the artifact. The bundled headers are installed to the directory specified byh_dir(which iszig-out/includeby default).
dependencyFromBuildZig §
Given a struct that corresponds to the build.zig of a dependency, b.dependencyFromBuildZig returns that same dependency. In other words, if you have already @imported a dependency's build.zig struct, you can use this function to obtain a corresponding Dependency:
// in consumer build.zig
const foo_dep = b.dependencyFromBuildZig(@import("foo"), .{});This function is useful for packages that expose functions from their build.zig files that need to use their corresponding Dependency, such as for accessing package-relative paths, or for running system commands and returning the output as lazy paths. This can now be accomplished through:
// in dependency build.zig
pub fn getImportantFile(b: *std.Build) std.Build.LazyPath {
const this_dep = b.dependencyFromBuildZig(@This(), .{});
return this_dep.path("file.txt");
}
// in consumer build.zig
const file = @import("foo").getImportantFile(b);Compiler §
x86 Backend §

The x86 backend is now passing 1765/1828 (97%) of the behavior test suite, compared to the LLVM backend. It is far enough along that it is sometimes useful while developing, mainly due to the fact that it offers dramatically faster compilation speed:
Benchmark 1 (8 runs): zig-0.12.0 build-exe hello.zig measurement mean ± σ min … max outliers delta wall_time 667ms ± 26.7ms 643ms … 729ms 1 (13%) 0% peak_rss 175MB ± 19.3MB 168MB … 223MB 1 (13%) 0% cpu_cycles 3.42G ± 532M 3.21G … 4.74G 1 (13%) 0% instructions 6.20G ± 1.05G 5.83G … 8.79G 1 (13%) 0% cache_references 241M ± 19.9M 234M … 291M 1 (13%) 0% cache_misses 48.3M ± 1.26M 47.7M … 51.4M 1 (13%) 0% branch_misses 35.3M ± 4.07M 33.7M … 45.4M 1 (13%) 0% Benchmark 2 (26 runs): zig-0.12.0 build-exe hello.zig -fno-llvm -fno-lld measurement mean ± σ min … max outliers delta wall_time 196ms ± 5.77ms 187ms … 208ms 0 ( 0%) ⚡- 70.6% ± 1.7% peak_rss 88.7MB ± 721KB 87.8MB … 90.4MB 2 ( 8%) ⚡- 49.3% ± 4.3% cpu_cycles 842M ± 6.01M 836M … 866M 1 ( 4%) ⚡- 75.4% ± 6.0% instructions 1.60G ± 9.62K 1.60G … 1.60G 0 ( 0%) ⚡- 74.1% ± 6.5% cache_references 56.6M ± 378K 56.0M … 57.3M 0 ( 0%) ⚡- 76.6% ± 3.2% cache_misses 8.43M ± 104K 8.30M … 8.79M 2 ( 8%) ⚡- 82.5% ± 1.0% branch_misses 7.20M ± 30.2K 7.15M … 7.28M 2 ( 8%) ⚡- 79.6% ± 4.4%
This backend can be accessed when compiling for an x86_64 target by passing the CLI options
-fno-llvm -fno-lld, or by setting the build system
flags use_llvm and use_lld on
std.Build.Step.Compile to false. This backend is
now able to compile many Zig projects, including the compiler itself.
Remaining tasks until it can be selected by default instead of LLVM for debug builds:
- 100% behavior tests passing
- Improved debug info
- Improved runtime performance
Windows Resources §
Zig now supports compiling (and cross-compiling) Windows resource scripts (.rc files) and .manifest files, and linking the resulting .res files into the resource table of PE/COFF binaries.
- Add a .rc -> .res compiler to the Zig compiler
- Add zig rc subcommand, a (cross-platform) drop-in replacement for rc.exe
- Add preliminary support for Windows .manifest files
See Zig is now also a Windows resource compiler for some use-cases of this feature and details of how to use it.
Linker §
Zig now supports ELF linking for x86_64, aarch64, and partial support for riscv64.
Dependency on LLD is expected to be dropped during the next release cycle.
The -fno-lld flag can be used to use Zig's linker where it is not currently the default.
Cache System §
This rather annoying bug is fixed now: error: StreamTooLong when recompiling; duplicate source files in cache manifest
The fix, which deduplicates files listed in the cache manifest, makes cache hits significantly faster. Data point: cache hit building hello world with static musl libc
Benchmark 1 (61 runs): master/zig build-exe hello.c -target native-native-musl -lc measurement mean ± σ min … max outliers delta wall_time 81.4ms ± 1.76ms 77.7ms … 87.1ms 1 ( 2%) 0% peak_rss 64.6MB ± 77.7KB 64.4MB … 64.7MB 0 ( 0%) 0% cpu_cycles 97.2M ± 1.04M 95.1M … 101M 1 ( 2%) 0% instructions 153M ± 11.1K 152M … 153M 0 ( 0%) 0% cache_references 2.21M ± 97.1K 2.05M … 2.54M 2 ( 3%) 0% cache_misses 529K ± 24.4K 486K … 600K 4 ( 7%) 0% branch_misses 409K ± 6.45K 397K … 437K 1 ( 2%) 0% Benchmark 2 (189 runs): cache-dedup/zig build-exe hello.c -target native-native-musl -lc measurement mean ± σ min … max outliers delta wall_time 25.8ms ± 1.26ms 23.9ms … 30.7ms 11 ( 6%) ⚡- 68.4% ± 0.5% peak_rss 65.2MB ± 61.8KB 65.1MB … 65.4MB 2 ( 1%) 💩+ 1.0% ± 0.0% cpu_cycles 41.2M ± 608K 40.1M … 46.3M 4 ( 2%) ⚡- 57.6% ± 0.2% instructions 64.3M ± 12.6K 64.3M … 64.4M 2 ( 1%) ⚡- 57.8% ± 0.0% cache_references 1.28M ± 34.5K 1.21M … 1.35M 0 ( 0%) ⚡- 41.9% ± 0.7% cache_misses 348K ± 18.6K 297K … 396K 0 ( 0%) ⚡- 34.2% ± 1.1% branch_misses 199K ± 1.34K 197K … 206K 6 ( 3%) ⚡- 51.2% ± 0.2%
Bug Fixes §
Full list of the 502 bug reports closed during this release cycle.
Many bugs were both introduced and resolved within this release cycle. Most bug fixes are omitted from these release notes for the sake of brevity.
Comptime Pointer Access §
Zig has had several long-standing bugs relating to accessing pointers at compile time. When attempting to access pointers in a non-trivial way, such as loading a slice of an array or reinterpreting memory, you would at times be greeted with a false positive compile error stating that the comptime dereference required a certain type to have a well-defined layout.
The merge of #19630 resolves this issue. In Zig 0.12.0,
the compiler should no longer emit incorrect compile errors when doing complex things with comptime memory.
This change also includes some fixes to the logic for comptime @bitCast; in particular,
bitcasting aggregates containing pointers no longer incorrectly forces the operation to occur at runtime.
This Release Contains Bugs §

Zig has known bugs and even some miscompilations.
Zig is immature. Even with Zig 0.12.0, working on a non-trivial project using Zig will likely require participating in the development process.
When Zig reaches 1.0.0, Tier 1 Support will gain a bug policy as an additional requirement.
Toolchain §
LLVM 17 §
This release of Zig upgrades to LLVM 17.0.6.
Zig now generates LLVM bitcode module files directly and then passes those to LLVM. This
means that a Zig compiler built without LLVM libraries can still produce .bc files,
which can then be passed to clang for compilation.
musl 1.2.4 §
Although musl v1.2.5 is now available upstream, this version of Zig continues to provide v1.2.4. The next release of Zig is expected to have the updated musl.
glibc 2.38 §
glibc versions 2.35, 2.36, 2.37, and 2.38 are now available when cross-compiling.
mingw-w64 §
Based on a suggestion from Martin Storsjö, Zig now tracks the latest master branch commit of mingw-w64.
Roadmap §

The major theme of the 0.13.0 release cycle will be compilation speed.
Some upcoming milestones we will be working towards in the 0.13.0 release cycle:
- Making the x86 Backend the default backend for debug mode.
- Linker support for COFF. Eliminate dependency on LLD.
- Enabling incremental compilation for fast rebuilds.
- Introduce Concurrency to semantic analysis to further increase compilation speed.
The idea here is that prioritizing faster compilation will increase development velocity on the Compiler itself, leading to more bugs fixed and features completed in the following release cycles.
It also could potentially lead to language changes that unblock fast compilation.
Async/Await Feature Status §
Async functions regressed with the release of 0.11.0 (the previous release to this one). Their future in the Zig language is unclear due to multiple unsolved problems:
- LLVM's lack of ability to optimize them.
- Third-party debuggers' lack of ability to debug them.
- The cancellation problem.
- Async function pointers preventing the stack size from being known.
These problems are surmountable, but it will take time. The Zig team is currently focused on other priorities.
Thank You Contributors! §

Here are all the people who landed at least one contribution into this release:
- Andrew Kelley
- Jakub Konka
- Jacob Young
- Matthew Lugg
- Robin Voetter
- Igor Anić
- Ryan Liptak
- Veikka Tuominen
- antlilja
- Carl Åstholm
- Luuk de Gram
- Michael Dusan
- Dominic
- Krzysztof Wolicki
- Casey Banner
- Ali Chraghi
- Nameless
- Ian Johnson
- David Rubin
- Meghan Denny
- Marc Tiehuis
- Techatrix
- Xavier Bouchoux
- Bogdan Romanyuk
- Pat Tullmann
- Frank Denis
- Tristan Ross
- Loris Cro
- Stephen Gregoratto
- xdBronch
- Evan Haas
- John Schmidt
- Ryan Zezeski
- expikr
- Elaine Gibson
- MrDmitry
- e4m2
- Adam Goertz
- Jan Philipp Hafer
- Jay Petacat
- Jonathan Marler
- Travis Staloch
- Wooster
- XXIV
- joadnacer
- Jae B
- Kai Jellinghaus
- Linus Groh
- frmdstryr
- Garrett Beck
- Josh Wolfe
- Karl Seguin
- Sahnvour
- february cozzocrea
- fn ⌃ ⌥
- Carter Snook
- Eric Joldasov
- Erik Arvstedt
- Gordon Cassie
- HydroH
- JustinWayland
- Lucas Santos
- Luis Cáceres
- Motiejus Jakštys
- Nguyễn Gia Phong
- Paul Berg
- Pavel Verigo
- Piotr Szlachciak
- Prokop Randáček
- Ratakor
- Stevie Hryciw
- SuperAuguste
- Zachary Raineri
- amp-59
- garrisonhh
- Alex Kladov
- Ben Crist
- Eric Eastwood
- Jan200101
- Jari Vetoniemi
- Jeremy Volkman
- Kang Seonghoon
- Manlio Perillo
- Markus F.X.J. Oberhumer
- Michael Ortmann
- Pascal S. de Kloe
- Philipp Lühmann
- Ruben Dimas
- Sean
- Tobias Simetsreiter
- Tom Read Cutting
- Tw
- Vlad Pănăzan
- cipharius
- jimying
- nikneym
- none
- ocrap7
- riverbl
- snoire
- tjog
- xEgoist
- Abhinav Gupta
- Adrià Arrufat
- Ahmed
- Alex
- Alexander Heinrich
- AlliedEnvy
- Ambareesh "Amby" Balaji
- Amir Alawi
- Andre Herbst
- Andre Weissflog
- Andreas Herrmann
- Anubhab Ghosh
- Arnau
- Artem Kolichenkov
- Aven Bross
- Banacial
- Becker A
- Ben Sinclair
- Brandon Black
- Brandon Botsch
- CPestka
- Chadwain Holness
- Chris Boesch
- Chris Burgess
- Christian Flicker
- Christiano Haesbaert
- Christofer Nolander
- Constantin Bilz
- Constantin Pestka
- Craig O'Connor
- Curtis Tate Wilkinson
- Daniel A.C. Martin
- Daniel Guzman
- David Gonzalez Martin
- DilithiumNitrate
- Dillen Meijboom
- DraagrenKirneh
- Emil Lerch
- Emil Tywoniak
- F3real
- Federico Stra
- Felix Kollmann
- Gregory Anders
- Gregory Mullen
- Guillaume Wenzek
- Gustavo C. Viegas
- Hashi364
- Hong Shick Pak
- Ian Kerins
- Igor Sadikov
- IntegratedQuantum
- Jacob G-W
- James Chen-Smith
- Jan Weidner
- Jeremia Dominguez
- Jiacai Liu
- Jim Calabro
- Joachim Schmidt
- Joel Gustafson
- Johan Jansson
- John Benediktsson
- Jordyfel
- Justus Klausecker
- Kamil T
- Karl Böhlmark
- Khang Nguyen Duy
- Kirk Scheibelhut
- Koakuma
- Lateef Jackson
- Lauri Tirkkonen
- Lee Cannon
- Leo Emar-Kar
- Leonardo Gatti
- Lewis Gaul
- LinuxUserGD
- Littleote
- Liviu Dudau
- LordMZTE
- Luca Ivaldi
- Lucas Culverhouse
- Maciej 'vesim' Kuliński
- Marcius
- Mason Remaley
- Matt Knight
- Matthew Wozniak
- Maximilian
- Michael Bradshaw
- Michael Lynch
- Michael Pfaff
- Michael Scott
- Michal Ziulek
- Mikko Kaihlavirta
- Minsoo Choo
- Mustafa Uzun
- Naboris
- Nan Zhong
- Niles Salter
- Nitin Prakash
- OK Ryoko
- PanSashko
- Paul Jimenez
- PauloCampana
- Peng He
- Phil Richards
- Prcuvu
- Purrie
- Pyry Kovanen
- Qusai Hroub
- Rafael Fernández López
- Rahul Prabhu
- Reokodoku
- Robinson Collado
- Roman Frołow
- Ryan Barth
- Samuel Fiedler
- Samuel Nevarez
- Scott Schwarz
- Sebastien Marie
- Simon Brown
- Stefan Su
- Stephen Gutekanst
- Tim Culverhouse
- Tobias Simetsreiter
- Tomasz Lisowski
- Vitalijus Valantiejus
- Winter
- andrewkraevskii
- arbrk1
- bfredl
- binarycraft007
- castholm
- cdrmack
- cfillion
- crayon
- cryptocode
- danielsan901998
- davideger
- dbandstra
- dhash
- dundargoc
- emberfade
- hdert
- iwVerve
- jacwil
- jaina heartles
- jd
- leap123
- lockbox
- loris
- mataha
- melonedo
- mllken
- ndbn
- notcancername
- pancelor
- paoda
- radar roark
- regeliv
- salo-dea
- sammy j
- tinusgraglin
- tison
- vinnichase
- yunsh1
- zhylmzr
- Андрей Краевский
Thank You Sponsors! §

Special thanks to those who sponsor Zig. Because of recurring donations, Zig is driven by the open source community, rather than the goal of making profit. In particular, these fine folks sponsor Zig for $50/month or more:
- Josh Wolfe
- Matt Knight
- Stevie Hryciw
- Jethro Nederhof
- Karrick McDermott
- José M Rico
- drfuchs
- Joran Dirk Greef
- Rui Ueyama
- bfredl
- Simon A. Nielsen Knights
- Stephen Gutekanst
- Derek Collison
- Daniele Cocca
- Rafael Batiati
- Aras Pranckevičius
- Terin Stock
- Loïc Tosser
- Kirk Scheibelhut
- Mitchell Hashimoto
- Brian Gold
- Paul Harrington
- Clark Gaebel
- Bun
- Marcus Eagan
- Ken Chilton
- Sebastian
- Will Manning
- Fulcrum Labs
- Alex Mackenzie at Tapestry VC
- Alok Parlikar
- Viktor Tratsevskyy
- johnpyp
- Huly® Platform™
- Reuben Dunnington
- Isaac Yonemoto
- Luuk de Gram
- Auguste Rame
- Jay Petacat
- Dirk de Visser
- Santiago Andaluz
- Andrew Mangogna
- Yaroslav Zhavoronkov
- Christian Wesselhoeft
- Anton Kochkov
- Max Bernstein
- James McGill
- Luke Champine
- AG.王爱国
- Wojtek Mach
- Nicola Larosa
- Daniel Hensley
- cryptocode
- Erik Mållberg
- Collin Kemper
- Fabio Arnold
- Tom Read Cutting
- Ross Rheingans-Yoo
- Emily A. Bellows
- Justin "J.R." Hill
- Mykhailo Tsiuptsiun
- Kiril Mihaylov
- Brett Slatkin
- Sean Carey
- Yurii Rashkovskii
- Benjamin Ebby
- Ralph Brorsen
- OM PropTech GmbH
- Alex Sergeev
- Pierre Curto
- Kemal Akkoyun
- Marco Munizaga
- Josh Ashby
- Chris Baldwin
- Malcolm Still
- Viktor Hellström
- Francis Bouvier
- Fawzi Mohamed
- Alve Larsson
- Nicolas Goy
- Ian Johnson
- Carlos Pizano Uribe
- Rene Schallner
- Linus Groh
- Jinkyu Yi
- jake hemmerle
- Will Pragnell
- Nathan Youngman
- Peter Snelgrove
- Jeff Fowler
- Nate
- Samu
- foxnne
- Christian Gibson
- 11sync.net
- impactaky
- Dylan Conway
- Hlib Kanunnikov
- merkleplant
- Omar AlSuwaidi