Devlog
This page contains a curated list of recent changes to main branch Zig.
Also available as an RSS feed.
This page contains entries for the year 2024. Other years are available in the Devlog archive page.
For Christmas: Self-Referential Global Values
Author: Matthew Lugg
I recently took it upon myself to tackle issue #131. This has been a long-standing bug in the compiler, dating way back to the earliest days of the C++ bootstrap compiler: it was the 9th oldest open issue in the Zig repository! Essentially, fixing it allows you to write code like this:
const S = struct { ptr: *const S, x: u32 };
// `foo` contains a pointer to itself
const foo: S = .{ .ptr = &foo, .x = 123 };
// Or:
// `a` contains a pointer to `b`, and...
// `b` contains a pointer to `a`
const a: S = .{ .ptr = &b, .x = 123 };
const b: S = .{ .ptr = &a, .x = 456 };
Previously, both of the examples above would have failed with a “dependency loop detected” error; now, they compile just as you expect (and the same works if they’re declared var, of course).
This issue had been open for so long because it actually requires a non-trivial extension to the compiler: separating semantic analysis for the type and value of container-level declarations. This is complicated further by the fact that some global declarations might not have a type annotation, and that some (such as extern declarations) have a type but no value. It also interacts with the work-in-progress incremental compilation feature in non-trivial ways, so we had to make sure we got that right. All in all, this resulted in a pretty bulky diff to the compiler.
Regardless, the point is, this now works on Zig master! If you have a use case for it, feel free to give it a try – and please do open an issue if you encounter any problems along the way.
Merry Christmas to those who celebrate!
Zig Bootstrap Porting Progress
Author: Alex Rønne Petersen
The zig-bootstrap project makes it possible to produce a Zig compiler to run on (almost) any target with minimal system dependencies on the build machine. As part of my recent port work on Zig, I made it a goal to get zig-bootstrap working on as many of our supported cross-compilation target triples (zig targets | jq -r .libc[]) as reasonably possible. I’m happy to report that this effort is now complete.
At time of writing, the list of target triples supported by zig-bootstrap is as follows:
aarch64-linux-(gnu,musl)aarch64-macos-noneaarch64-windows-gnuaarch64_be-linux-(gnu,musl)arm[eb]-linux-(gnu,musl)eabi[hf]loongarch64-linux-(gnu,gnusf,musl)mips[el]-linux-(gnu,musl)eabi[hf]mips64[el]-linux-(gnu,musl)abi(64,n32)powerpc-linux-(gnu,musl)eabi[hf]powerpc64-linux-muslpowerpc64le-linux-(gnu,musl)riscv(32,64)-linux-(gnu,musl)s390x-linux-(gnu,musl)thumb[eb]-linux-musleabi[hf]thumb-windows-gnux86-linux-(gnu,musl)x86-windows-gnux86_64-linux-(gnu,musl)[x32]x86_64-macos-nonex86_64-windows-gnu
The latest list can be found here.
If you’ve been itching to run Zig on some unusual or obscure target, please take zig-bootstrap for a spin and see how it works for you. If you run into any build issues, please report those on the zig-bootstrap repository; issues with running the built compiler should be reported on ziglang/zig.
The Unreasonable Effectiveness of Naming Integers
Author: Andrew Kelley
Lately my Zig code has started to look like this in all my projects:
/// Uniquely identifies a section index across all objects. Each Object has a section_start field.
/// By subtracting that value from this one, the Object section index is obtained.
const SectionIndex = enum(u32) {
_,
};
/// Index into object_function_imports
pub const ObjectFunctionImportIndex = enum(u32) {
_,
};
/// Index into `object_global_imports`
pub const ObjectGlobalImportIndex = enum(u32) {
_,
};
/// Index into object_table_imports.
pub const ObjectTableImportIndex = enum(u32) {
_,
};
/// Index into `function_imports`.
pub const FunctionImportIndex = enum(u32) {
_,
};
/// Index into `global_imports`.
pub const GlobalImportIndex = enum(u32) {
_,
};
/// Index into `table_imports`.
pub const TableImportIndex = enum(u32) {
_,
};
/// Index into `memory_imports`.
pub const MemoryImportIndex = enum(u32) {
_,
};
/// Index into `output_globals`.
pub const GlobalIndex = enum(u32) {
_,
};
/// Index into `functions`.
pub const FunctionIndex = enum(u32) {
_,
};
/// Index into object_functions
pub const ObjectFunctionIndex = enum(u32) {
_,
pub fn toOptional(i: ObjectFunctionIndex) OptionalObjectFunctionIndex {
const result: OptionalObjectFunctionIndex = @enumFromInt(@intFromEnum(i));
assert(result != .none);
return result;
}
};
/// Index into object_functions, or null.
pub const OptionalObjectFunctionIndex = enum(u32) {
none = std.math.maxInt(u32),
_,
pub fn unwrap(i: OptionalObjectFunctionIndex) ?ObjectFunctionIndex {
if (i == .none) return null;
return @enumFromInt(@intFromEnum(i));
}
};
It’s uncanny how effective it is to avoid bugs by simply naming integers and thereby giving Zig’s type system a chance to catch mistakes. It’s extremely annoying and time consuming to troubleshoot this kind of mistake at runtime, but it’s trivial to solve when you get a compile error from a type mismatch.
Anonymous Struct Types Removed
Author: Matthew Lugg
Rejoice, ye faithful; the days of undocumented structural aggregate types are over!
Until recently, Zig had the notion of an “anonymous struct type”. When you wrote .{ .x = 123 } with no result type, it would give this value an “anonymous struct” type, which is a special kind of struct which can coerce to other types based on structure rather than identity. In other words, this worked:
test "coerce anonymous struct" {
const foo = .{ .x = 123 };
const S = struct { x: ?u32 };
// It's true that `@TypeOf(foo) != S`, and yet...
const bar: S = foo; // ...this works!
try std.testing.expect(bar.x.? == 123);
}
const std = @import("std");
A little bit of trivia: this existed because a long time ago, Zig didn’t actually have the concept of a “result type”, so all type annotations worked via coercions like that!
I proposed removing this system last year, and finally got around to actually doing it last week. You can still write .{ .x = 123 } without a result type, but it’s given a “normal” struct type, with no magical coercions allowed. So now, the above code example fails just like you’d expect:
example.zig:5:20: error: expected type 'example.test.coerce anonymous struct.S', found 'example.test.coerce anonymous struct__struct_90'
const bar: S = foo; // ...this works!
^~~
example.zig:2:18: note: struct declared here
const foo = .{ .x = 123 };
~^~~~~~~~~~~~
example.zig:3:15: note: struct declared here
const S = struct { x: ?u32 };
^~~~~~~~~~~~~~~~~~
Good riddance!
File Watching Implemented for kqueue
Author: Andrew Kelley
I knocked out #20599 on a plane ride last week (coincidentally on the way to a KQ tournament), so if you’re tracking master branch, you can now use the zig build --watch feature on macOS, FreeBSD, OpenBSD, NetBSD, DragonFlyBSD, and Haiku.
This feature tracks all file system inputs, automatically repeating invalidated build steps. It can be quite handy when refactoring a codebase using a terminal-based workflow since it means seeing instant feedback when any build inputs - source code or otherwise - are updated.
KQueue allows placing a watch on an open directory handle, but the event does not indicate the name of the changed file within any given directory. This is no problem for the Zig Build System. If any directory that contains watched files are triggered, the respective steps are invalidated, and then those steps use fstat to determine if the cached artifacts are still valid.
CI Coverage Added for Incremental Compilation
Author: Matthew Lugg
Over the last few months, myself and Jakub have been working hard on incremental compilation, where the compiler can “remember” parts of a previous build and only re-compile the code that changed. We just hit an important milestone here: our CI test suite now includes our “incremental compilation” tests! This set of tests is small right now, but will grow rapidly as we fix bugs and, eventually, fuzz test the implementation.
You can find all our incremental compilation test cases here. The CI runs all of them on x86_64-linux with the self-hosted x86_64 backend, as well as on a few targets with the C backend (-ofmt=c). It’s approaching the point where you can start to use incremental compilation in some very basic cases; for instance, I’ve recently managed to perform an incremental update on Andrew’s Tetris clone.
If you’re using a master build of Zig on Linux on x86_64, you can try playing with incremental compilation right now with this command:
zig build -fincremental --watch
(Make sure your Step.Compile has .use_llvm = false, .use_lld = false, so Zig doesn’t try to use LLVM!)
Beware, though, that you’ll run into bugs pretty quickly, including false positive compile errors and even miscompilations; use at your own risk.
New Devlog Structure
Author: Loris Cro
The devlog has switched to a per-year pre-sharded structure to avoid the issue of having a page that grows indefinitely.
NOTE: the RSS feed link has not changed. No action needed from RSS feed consumers. Cached links to older entries might become stale, but new entries from now on will have the correct link.
If you want to get a similar setup going for your personal blog, check out https://github.com/kristoff-it/zine-devlog-examples
loongarch64 added to the download page
Author: Andrew Kelley
Thanks to contributions from YANG Xudong and Alex Rønne Petersen, along with upgrading to LLVM 19, loongarch64 support in Zig is progressed enough that zig-bootstrap works for this target. In celebration, I have added loongarch64-linux to the download page.
2024-09-16
Author: Andrew Kelley
I’ve been porting stb_truetype.h to Zig on the side. Check out this snippet:
{
float sum = 0;
for (i=0; i < result->w; ++i) {
float k;
int m;
sum += scanline2[i];
k = scanline[i] + sum;
k = (float) STBTT_fabs(k)*255 + 0.5f;
m = (int) k;
if (m > 255) m = 255;
result->pixels[j*result->stride + i] = (unsigned char) m;
}
}
⬇️
{
var sum: f32 = 0;
for (scanline, scanline2, result.pixels[j*result.stride..][0..result.w]) |s, s2, *p| {
sum += s2;
p.* = @min(@abs(s + sum)*255 + 0.5, 255);
}
}
Ahh, much better.
Zig tokenizer updated to use labeled switch statements
Author: Andrew Kelley
Now that Matthew landed labeled switch continue syntax, it’s time to start using it.
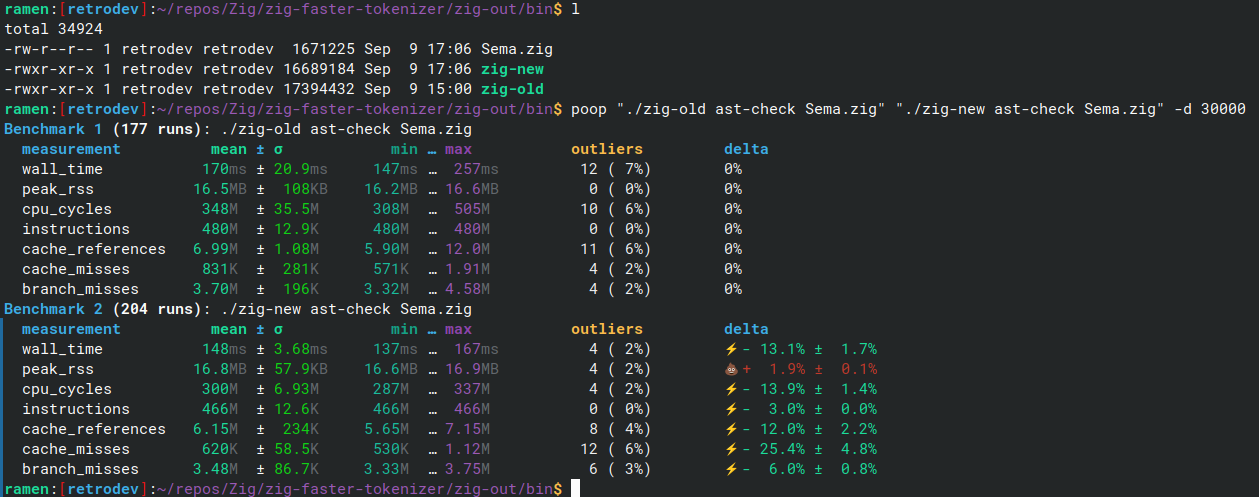
Eric Petersen swooped in for a first-time contribution, updating Zig’s tokenizer to use the new syntax, measuring a 13% wall time performance increase for the zig ast-check command:
This line of code tickles me:
state: switch (State.start) {